«Агент» — одно из самых затёртых слов в разговорах про AI за последний год. За ним прячут что угодно: от чат-бота с кнопками до автономной системы, которая сама принимает решения и сама лезет в ваши данные. Давайте разложим, что такое AI-агент на самом деле, чем он отличается от ассистента и обычной нейросети — и, главное для меня, как понять, что ему вообще можно доверять.
Сразу про угол. Я смотрю на это глазами аналитика и AI-энтузиаста, а не ML-инженера: модели я не обучаю — я их применяю. Каждый день, в маркетинговой аналитике, по большей части в медицине и фарме. Поэтому и примеры будут оттуда: настройка Яндекс Метрики и GTM, трекинг переходов в аптеку и воронок регистрации, разбор расхождений между BI и счётчиком. И поэтому же я буду занудой в вопросах измеримости — это профдеформация, но в нашем деле она спасает бюджеты.
Почему модель в одиночку упирается в потолок
Прежде чем добраться до агентов, вернёмся на шаг назад — к самой модели. Почти за любым чат-ботом, ассистентом и «нейросеткой» стоит большая языковая модель (LLM): её обучили на огромном массиве данных, и именно она генерирует ответы. Агент, как мы увидим дальше, — это надстройка над такой моделью. Поэтому сначала честно разберёмся, что модель умеет, а что нет сама по себе.
А не может она вот чего. Модель знает только то, что было в обучающих данных. Это сразу две стены: она не в курсе того, что появилось после обучения, и ничего не знает про ваш проект — как у вас устроено хранение данных, что вы называете конверсией, по каким правилам размечаете трафик. Дообучить её под себя можно, но это деньги, данные и время — дорогая операция, которую не сделаешь под каждую рабочую задачу.
Покажу на примере. Я почти никогда не прошу у модели готовый ответ напрямую. Типичная задача звучит иначе: «помоги собрать отчёт по переходам в аптеку с расчётом по всем ключевым моделям атрибуции». Но спроси модель холодную, без контекста — и она не знает, ни что у нас есть ClickHouse с выгрузками Яндекс Метрики и Директа, ни как разложены таблицы, ни что в этом проекте считается «переходом в аптеку», ни какие модели атрибуции мы используем. И тут проявляется классическая проблема галлюцинаций. Без контекста модель опирается на единственное, что у неё есть, — на закономерности из обучающих данных: выдаёт усреднённое «как это обычно устроено у всех». Звучит уверенно, но по сути это правдоподобный шаблон — названия таблиц, поля и логика расчёта, собранные из тысяч чужих проектов, которые к нашей реальности отношения не имеют.
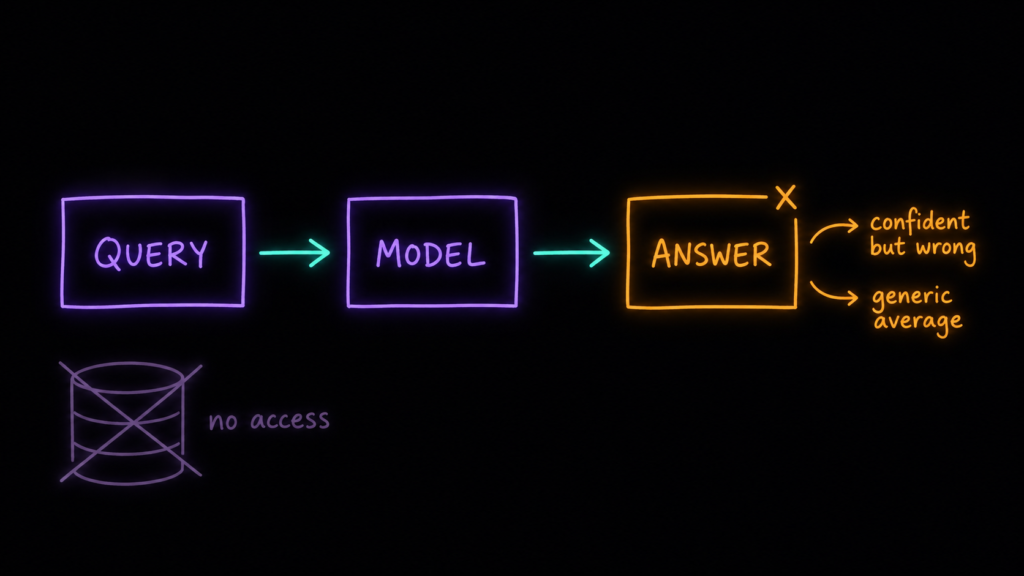
Для аналитика это красный флаг: уверенность ответа ничего не говорит о его правдивости. Значит, в одиночку модель — так себе помощник в прикладной задаче. Полезной она становится только в связке с контекстом и инструментами — с контекста и начнём.
Compound AI: магия не в модели, а в системе вокруг неё
Я не жду ответа из головы, а сначала даю модели прочитать документацию по проекту, выстроенную от общего к частному:
- бизнес — чем компания вообще живёт и что для неё целевое действие,
- метрики — что мы считаем главным, как эти метрики определены и по какой логике сходятся,
- данные — какие таблицы и датасеты лежат в ClickHouse, что в выгрузках Метрики и Директа, что в этом проекте называется «переходом в аптеку».
Порядок не случайный: модели, как и новому аналитику, сначала нужен бизнес-смысл, а уже потом таблицы — иначе она схватит технически похожую колонку, которая считает совсем не то. Теперь на тот же вопрос — «помоги собрать отчёт по переходам в аптеку» — модель отвечает не наугад, а спускается по документации сверху вниз: понимает, зачем нужен отчёт, находит нужную метрику и выходит на правильные таблицы и логику расчёта.
У этого приёма есть имя — RAG (retrieval-augmented generation): модель не выдумывает ответ, а сначала достаёт нужный фрагмент из базы знаний и отвечает уже по нему. Ключевое здесь — ответ можно проследить до источника: не «нейросеть так посчитала», а «вот конкретная цель в Метрике» или «вот пункт UTM-регламента, по которому мы размечаем QR-коды». Это про проверяемость, а в неё я верю куда больше, чем в цифру из воздуха.
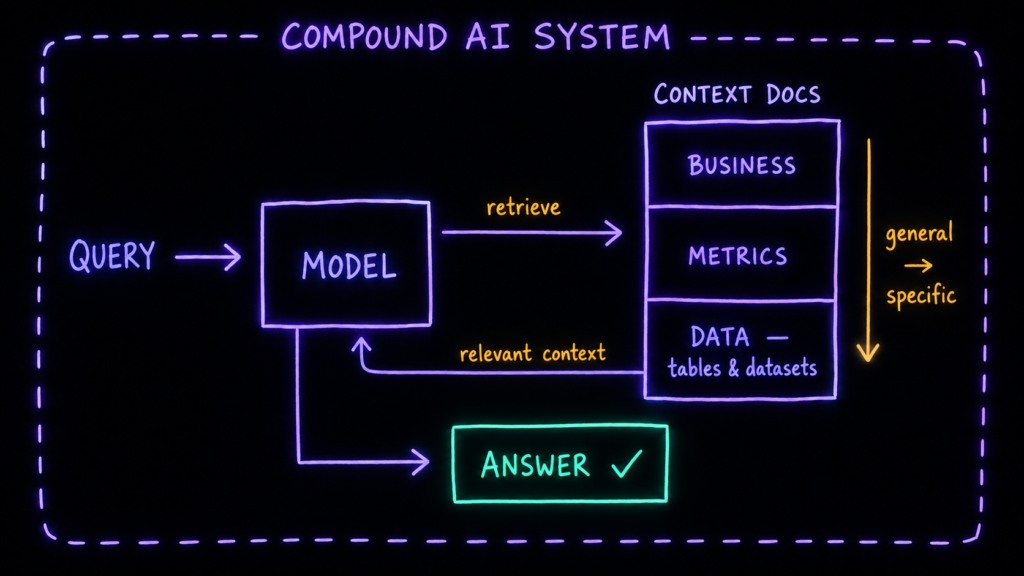
А RAG — лишь самый ходовой пример того, что называют compound AI system, составной системой. Идея простая: магия включается не от самой модели, а когда её достраивают обвязкой — поиском по базе, проверкой ответа, разбивкой сложного запроса на части — и встраивают в реальный процесс. Модель тут лишь один из модулей.
Тот же принцип я применяю к себе. Весь контекст проекта — от расшифровок встреч и структуры бизнеса до таблиц и UTM-разметки — лежит у меня в локальной базе знаний в Obsidian, и она работает как RAG-слой: модель сама подтягивает оттуда нужное под задачу. В этом виден сдвиг последних лет: раньше все гнались за «идеальным промптом», теперь фокус на контекст-инженерии — накопленный контекст со временем оказывается ценнее самой модели.
И контекст — только первый шаг. Готовый ответ я у модели почти никогда не прошу напрямую, а веду её по этапам:
→ описываю задачу — что нужно, какие данные есть, какие подводные камни я уже знаю,
→ прошу не бросаться решать, а предложить варианты и задать уточняющие вопросы,
→ выбираю подход и прошу разложить его на этапы — план до реализации,
→ и только потом реализуем: модель пишет кросс-чеки и объясняет их, или я проверяю результат сам.
Почему такой пошаговый разговор вообще работает (рассуждение, ReAct) и как проверять результат (измеримость) — разберём дальше. Суть простая: дело не в одном удачном запросе, а в контексте и дисциплине.
Кто у руля: программа или сама модель
У любой составной системы есть логика управления — кто решает, по какому пути идти к ответу. Назовём это control logic. Тут и проходит главный водораздел — между двумя полюсами.
Первый полюс — программа у руля. Путь к ответу задал я, человек. Классический RAG из прошлого раздела как раз такой: что бы ни спросили, система всегда идёт в один и тот же источник — скажем, в наш слой веб-аналитики. Спросишь «сколько было переходов в аптеку с платного трафика» — ответит, данные на месте. А спросишь «сколько из этих переходов превратилось в реальные покупки» — упрётся: продажи живут в офлайне и в CRM, а путь жёстко прошит на веб-аналитику, свернуть в другой источник система не умеет. Это режим «думай быстро»: действуй как запрограммировано, не отклоняйся от инструкции.
Второй полюс — модель у руля. Логику отдаём языковой модели: даём ей сложную задачу и просим самой разбить её на шаги и построить план. Это режим «думай медленно»: сначала план, потом по кусочку, где застрял — перестрой план. И вот когда модель управляет логикой — это и есть агентный подход (agentic).
Аналогия, которая мне заходит: задай человеку сложный вопрос. Выпалит первое, что пришло в голову, — скорее всего, промахнётся. Разобьёт на части, поймёт, где нужна внешняя помощь, потратит вечер — попадёт куда вернее. Агент работает по второй схеме.
Тот же водораздел можно увидеть со стороны пользователя — как реактивность против проактивности. Под этим углом удобно развести три термина, которые в чатах вечно путают:
Генеративный AI — реактивный. Ждёт промпт, генерирует контент (текст, картинку, код) и на этом останавливается. Сам следующий шаг не делает: предлагает варианты, а человек их курирует.
AI-ассистент — тоже реактивный, но заточен помогать по запросу. Работает как пинг-понг: промпт → ответ, промпт → ответ. Без вашего следующего удара ракеткой стоит на месте.
AI-агент — проактивный. Ему нужен только стартовый промпт-цель, а дальше он сам идёт к ней в несколько шагов, с минимальным участием человека (как именно — разберём в следующем разделе).
Первые два — это, по сути, левый полюс: путь либо в один проход, либо задан вами. Агент — правый: маршрут он прокладывает сам.
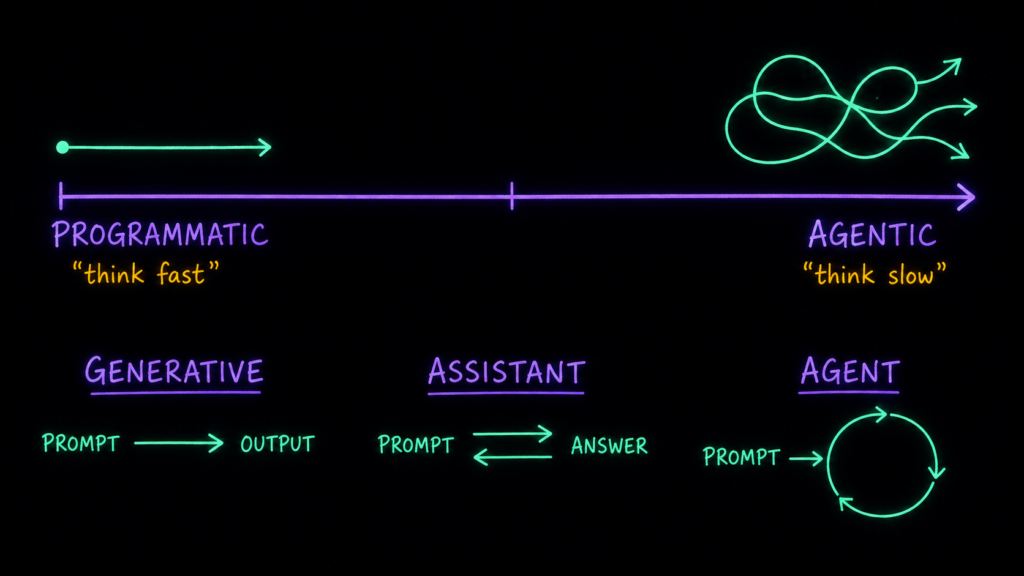
И тут снова включается аналитик. Слово «проактивный» красиво звучит на лендинге, но на деле означает, что агент принимает решения за вас. А раз так — главный вопрос не «насколько он автономный», а «как мы убедимся, что его решения верны». К измеримости вернёмся в конце, держим в уме.
Из чего собран агент: рассуждение, действие, память
Мы выяснили, что агент — это модель, которой отдали руль. Теперь разложим его на способности — их три.
Рассуждение (reason). Модель — в центре решения: вместо мгновенного ответа она сначала строит план и прогоняет цепочку рассуждений (chain of thought) — иногда её показывают, но чаще модель держит её внутри. Именно вокруг этой способности за последние пару лет всё и закрутилось. Сначала рассуждение оформили в отдельный класс моделей — o1 у OpenAI, следом DeepSeek R1: их специально учили прогонять цепочку рассуждений перед ответом. Но очень быстро это перестало быть отдельным классом и переехало внутрь флагманов: сегодня у Claude (Opus 4.8, Sonnet 4.6) рассуждение — это просто переключаемый режим, можно попросить «подумать подольше», а можно ответ сразу; то же самое появилось в ChatGPT и у других. Когда чат-бот замирает с подписью «думает…» — это он и есть. И ровно это рассуждение работает движком под капотом кодинг-агентов вроде Cursor и Claude Code.
Действие (act). Чтобы влиять на мир, модель вызывает инструменты — внешние куски программы, и сама решает, когда и как их дёрнуть. Инструментом может быть почти что угодно: сходить почитать страницу на сайте, загуглить незнакомый термин, дёрнуть API рекламного кабинета за расходами, выполнить bash, чтобы пролистать файлы документации, прогнать расчёт в Jupyter-ноутбуке. Я, кстати, почти никогда не даю агенту прямой доступ к базе и не прошу «выполни вот этот SQL» — прошу написать ноутбук, который запущу сам и посмотрю результат. Так у каждого действия остаётся артефакт, который видно и можно перепроверить.
И тут вторая важная штука. Ещё недавно под каждый такой инструмент разработчик писал отдельную одноразовую интеграцию. В конце 2024-го Anthropic представил MCP (Model Context Protocol), и он за полтора года стал де-факто стандартом — чем-то вроде «USB-C для AI-инструментов»: один разъём вместо десятка частных интеграций.
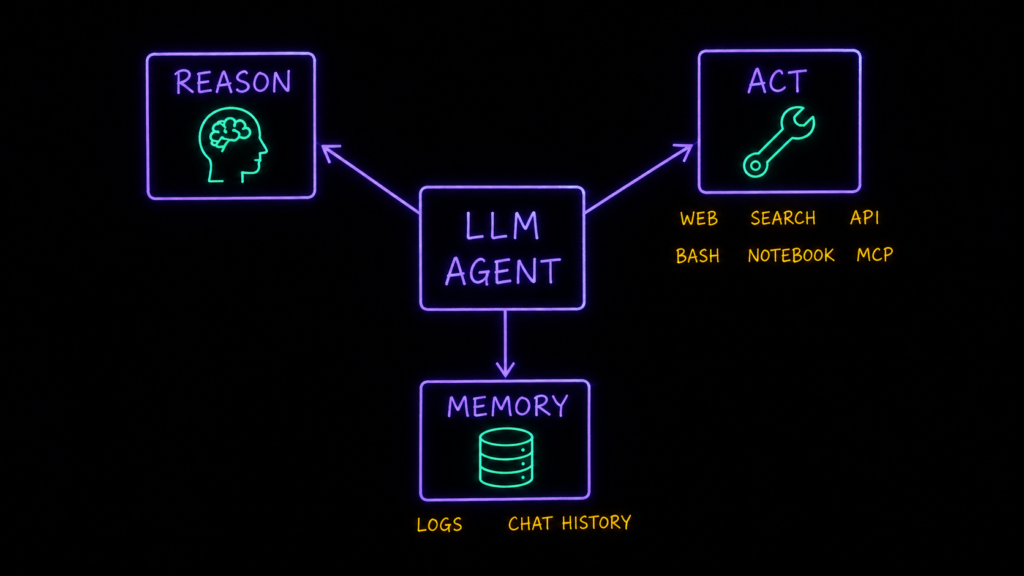
Память (memory). Два смысла. Первый — рабочая память хода решения: план, журнал вызванных инструментов, использованные источники и промежуточные артефакты. Само внутреннее рассуждение модель часто прячет, но наружу как раз важно сохранять этот журнал — его потом можно поднять и перепроверить. Второй смысл — история ваших диалогов, чтобы опыт был персональным, а не «здравствуйте, мы впервые». У меня оба вида памяти лежат файлами рядом с проектом — и это, опять же, проверяемо: всегда видно, на что агент опирался.
ReAct: как агент крутит цикл, пока не дойдёт до ответа
Самый известный способ собрать агента — паттерн ReAct, по имени видно: Reason + Act. Появился он ещё в 2022-м и с тех пор оброс надстройками — рефлексией, памятью, несколькими агентами, — но базовый цикл у всех этих схем один:
- задача приходит в модель с установкой: думать медленно и сперва составить план,
- модель строит план и пробует действовать (act): решает, нужен ли внешний инструмент, и дёргает его,
- получает результат и наблюдает (observe): это вообще ответ на вопрос или ошибка?
- если не то — перестраивает план и заходит на новый круг. И так до финального ответа.
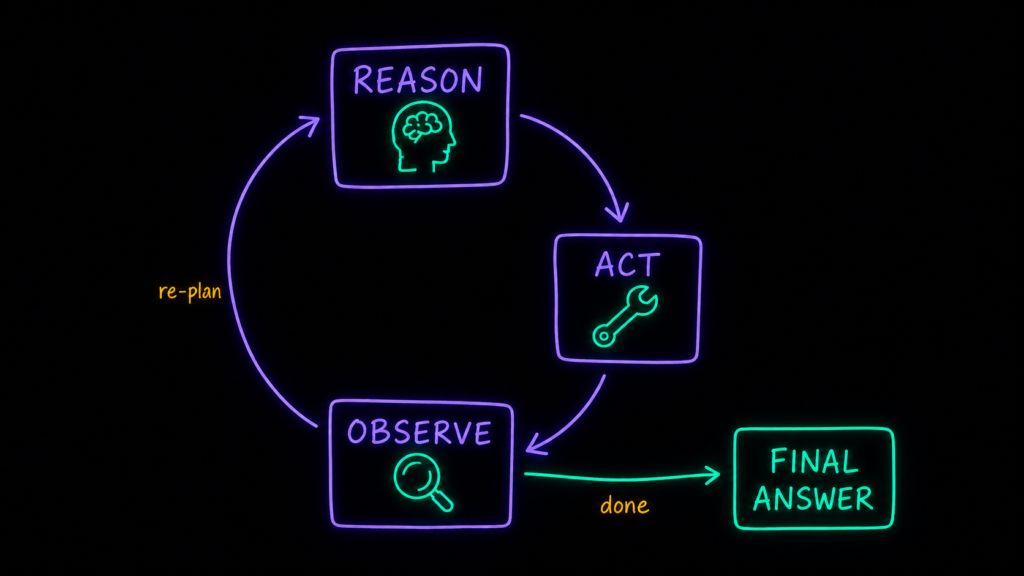
Покажу на задаче, близкой к моей кухне. Представьте, что я отдаю агенту вопрос: «27 февраля выкатили новый CTA “Купить” — не просела ли из-за этого конверсия в переходы в аптеку?». Сложная задача, и агент дробит её сам:
- достаёт мобильную конверсию в аптеку до и после релиза → видит, что общая почти не изменилась: была 1,38%, стала 1,41%,
- не останавливается на этом (тут заранее прописанный путь бы и оборвался) — наблюдает, что вывод подозрительно ровный, и перестраивает план: разложить по сегментам,
- бьёт по типам трафика → платный вырос заметно (1,55% → 1,80%), а органика просела (0,82% → 0,60%),
- замечает аномалию в органике и заходит ещё на круг: лезет в состав трафика и находит, что после внешнего поискового обновления выросла доля визитов на информационные страницы — то есть дело не в CTA, а в структуре входящего трафика.
План я ему не давал — он построил его сам по ходу, перестраивая после каждого наблюдения. Вот это и отличает агента от обычного скрипта: путей много, и под сложную задачу он соберёт нужный. Кстати, сам разбор — не выдумка, а реальный post-release кейс из фармы (цифры изменены); здесь я лишь показываю, как ту же логику прогнал бы агент.
И сразу честная оговорка, без неё нельзя: каждый шаг этого цикла — место, где агент может ошибиться. Достать не тот сегмент, молча взять не ту модель атрибуции, выдумать причинно-следственную связь там, где её нет. Поэтому финальный вывод такого агента я бы не отпускал в презентацию без сверки — но к тому, как его проверять, ещё вернёмся.
Ползунок автономности: где агент нужен, а где только мешает
Агент мощный и гибкий — и именно поэтому велик соблазн пихать его в каждую задачу. А главный практический вывод обратный: у автономности есть ползунок, и выкручивать его на максимум не всегда умно. Тот, кто проектирует систему, выбирает компромисс под конкретную задачу.
Узкая, чётко определённая задача — выгоднее программный путь. Регулярный отчёт по UTM-срезам или дашборд с фиксированными KPI всегда идёт одним и тем же маршрутом — незачем гонять агента, он будет лишь зря перебирать лишние шаги. Жёсткий путь отработает каждый запрос одинаково: быстро, дёшево, предсказуемо.
Сложная, разнообразная задача — тут агент оправдан. «Разберись, что не так с трафиком вот этой медийной площадки» — запрос, который каждый раз ведёт по новому пути: глянуть отказы, потом скролл, потом meaningful actions, потом карту кликов. Прописать заранее каждый маршрут нереально, проще дать модели порулить.
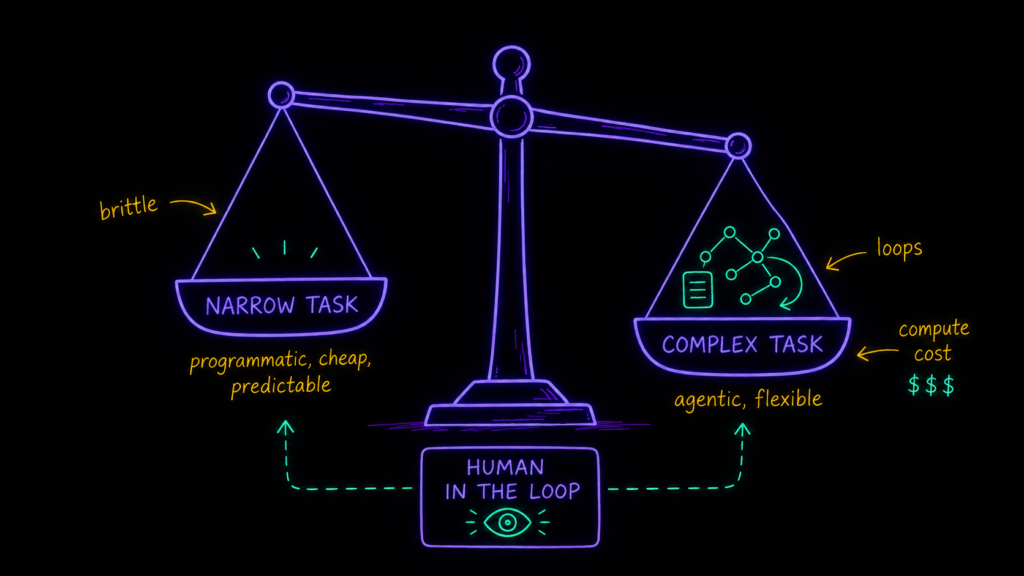
Как аналитик добавлю свой критерий: сколько стоит ошибка и насколько она заметна. Если выход агента легко проверить и цена промаха копеечная — автономии можно дать больше. Если решение уходит дальше по конвейеру и ошибку потом уже не отловишь — крутим ползунок влево и ставим человека в контур. В медицине и фарме это вообще не обсуждается: тут и цена ошибки высокая, и 152-ФЗ с требованиями к персональным и медицинским данным — так что human in the loop не вежливая опция, а часть конструкции.
И отдельно — про сами данные: персональные и медицинские нельзя передавать во внешние модели без правового основания. Нужны обезличивание, договор/DPA с провайдером и понятный контур хранения — где именно лежат данные и у кого к ним доступ. В фарме это часть техзадания, а не пожелание.
Стоит помнить и про грабли. Агенты хрупкие: чуть поменял формулировку — поплыли результаты. Могут залипнуть в петле и ходить кругами. И они прожорливые — гонять автономного агента без присмотра дорого по вычислениям. Всё это аргументы не против агентов, а за трезвый выбор положения ползунка.
И про время. Когда об этом ползунке заговорили, агенты были в самом начале пути — сейчас они заметно автономнее: кодинг-агенты и computer-use работают подолгу без вмешательства, а надёжность подросла вместе с рассуждением. От этого соблазн выкрутить ползунок на максимум только сильнее — и тем ценнее дисциплина включать автономию там, где она оправдана, а не везде подряд.
Измеримость: как понять, что агент не врёт
Вот мы и дошли до раздела, без которого я бы статью не отпустил. Агент по определению принимает решения за нас — значит, доверять ему вслепую нельзя, его нужно мерить. Несколько опор, которыми пользуюсь сам:
- Привязка к источнику. Хороший контур всегда оставляет след: вот данные, вот цель в Метрике, вот SQL-запрос, на которые опирался ответ. Если следа нет — это не ответ, а гадание с уверенным лицом.
- Наблюдаемость шагов. Журнал действий агента — план, вызовы инструментов, источники — не игрушка, а аудит; под это уже есть инструменты-трейсеры. Я хочу видеть, какой план агент построил и где свернул не туда, а не только финальную фразу в презентации.
- Эталоны и кросс-чеки (evals). Гонять агента на задачах с заранее известным правильным ответом — те же проверки, что я ставлю в любом расчёте.
- Человек на стыке. Не на каждом шаге, а на выходе — перед тем как вывод уйдёт в презентацию или в решение. Последняя сверка глазами, прежде чем цифре поверят.
Вывод простой: автономность хороша ровно настолько, насколько вы умеете её проверять. AI-агент без измеримости — это красивая демка, а не рабочий инструмент. А в фарме — ещё и риск, который никто не подписывал.
Что в итоге
Если совсем коротко: агент = модель, которой отдали управление логикой и дали способности рассуждать, действовать через инструменты и помнить. Появляется он не из самой модели, а из системы вокруг неё (compound AI), и живёт на ползунке между жёсткой программой и полной автономией. За последние пару лет картинка только окрепла: рассуждение из отдельного класса моделей превратилось в штатный режим флагманов, инструменты стандартизировал MCP, а рынок ушёл от «идеального промпта» к проектированию контекста.
Мой угол на всё это не меняется: чем больше решений агент принимает за нас, тем важнее уметь его проверять. Особенно там, где по этим решениям двигаются реальные бюджеты и реальные пациенты.
А вы уже пускали агента в реальный аналитический процесс — и как решали вопрос доверия к его выводам?
Полезные ссылки
- The Shift from Models to Compound AI Systems – Berkeley AI Research (BAIR), 2024 — про compound AI
- bair.berkeley.edu
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks – оригинальная статья про RAG, 2020
- arxiv.org
- Разбор ReAct в блоге Google Research
- research.google
- Introducing the Model Context Protocol
- www.anthropic.com
- Спецификация MCP
- modelcontextprotocol.io