Хорошая примета: если одну идею независимо переизобретают несколько раз — она рабочая. С базой знаний для AI-агентов так и выходит. Энтузиасты собирали вики из markdown задолго до хайпа. Карпатый описал паттерн в гисте — короткой заметке на GitHub — коротко и громко, и его подхватили. А 13 июня 2026-го Google выпустил под это открытый стандарт — Open Knowledge Format. Три захода к одной идее с разных сторон — самое время присмотреться.
В агентстве я каждый день переключаюсь между клиентами и их задачами – и у каждого свой контекст: своё хранилище, своя разметка, своя бизнес-модель и цели. Сложный SQL давно пишут агенты вроде Claude Sonnet и GPT-5 — реальная боль не в нём. Боль в том, что модели каждый раз заново объясняешь, как устроен именно этот бизнес. Про это и поговорим.
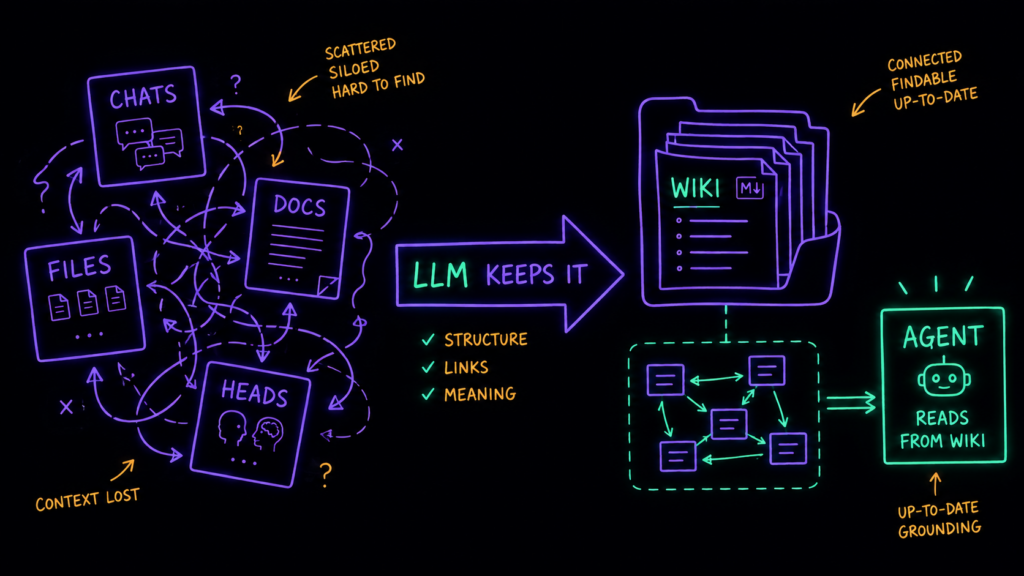
Почему обычный RAG упирается в потолок
Большинство из нас познакомились с «AI поверх своих документов» в формате RAG: загружаешь пачку файлов, на каждый вопрос модель находит подходящие куски и собирает из них ответ. Работает. Но есть встроенный потолок: модель переоткрывает знание с нуля на каждом запросе. Ничего не копится. Задал тонкий вопрос, ответ на который надо синтезировать из пяти документов — и модель каждый раз заново ищет и сшивает те же фрагменты. Так устроены и загрузка файлов в чат, и большинство RAG-обвязок.
Дело не в том, что RAG плохой, — он просто ничего не строит. Результат не накапливается и плохо воспроизводится: связь, которую модель нашла сегодня, завтра ей искать заново, и не факт, что найдётся та же. Для разовой справки сойдёт. Для инструмента, на который опираешься каждый день, — слабый фундамент.
Карпатый в своём гисте «LLM Wiki» предлагает зайти иначе.
База знаний, которую AI ведёт сам
Идея простая, но переворачивает схему. Вместо того чтобы доставать ответы из сырых документов на каждом запросе, LLM инкрементально строит и поддерживает живую вики — структурированный набор связанных markdown-файлов, который стоит между тобой и исходными документами. Добавил новый источник — модель его не просто индексирует «на потом». Она читает, достаёт суть и встраивает в существующую вики: обновляет страницы сущностей, правит сводки по темам, помечает, где новые данные противоречат старым. Знание компилируется один раз — и дальше держится в актуальном состоянии, а не выводится заново на каждый вопрос.
Ключевое слово здесь — накопление. Кросс-ссылки уже проставлены. Противоречия уже отмечены. Сводка уже учитывает всё, что ты прочитал. С каждым новым источником и каждым заданным вопросом вики становится богаче.
Важная деталь: вики пишет не человек. Её пишет и поддерживает модель. За тобой — поиск источников, направление разбора и правильные вопросы. За моделью — вся рутина: суммирование, кросс-ссылки, раскладка по файлам, сверка одного с другим. Сам Карпатый описывает это так: агент открыт с одной стороны, вики в редакторе — с другой; он правит, ты на ходу читаешь результат, ходишь по ссылкам, смотришь граф.
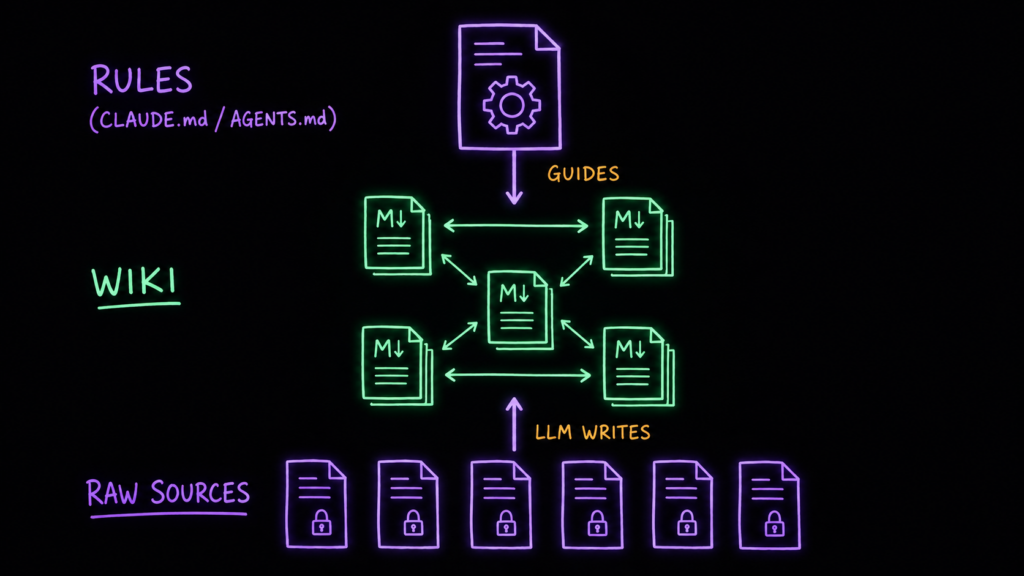
Три слоя: источники, вики и схема
Под капотом — три слоя, и их полезно не путать.
- Источники — твоя коллекция исходных документов: статьи, отчёты, выгрузки, заметки. Слой неизменяемый: модель из него только читает, но никогда не правит. Это источник правды.
- Вики — папка markdown-файлов, которые сгенерировала модель: сводки, страницы сущностей и концептов, обзор, синтез. Этим слоем модель владеет целиком — создаёт страницы, обновляет их при новых источниках, держит кросс-ссылки. Ты читаешь, модель пишет.
- Схема — документ, который объясняет модели, как устроена вики, какие в ней соглашения и по каким правилам с ней работать. Для Claude Code это
CLAUDE.md, для Codex —AGENTS.md. Именно этот файл превращает модель из универсального помощника в дисциплинированного хранителя базы. Вы дописываете его вместе, по мере того как нащупываете, что работает в вашем домене.
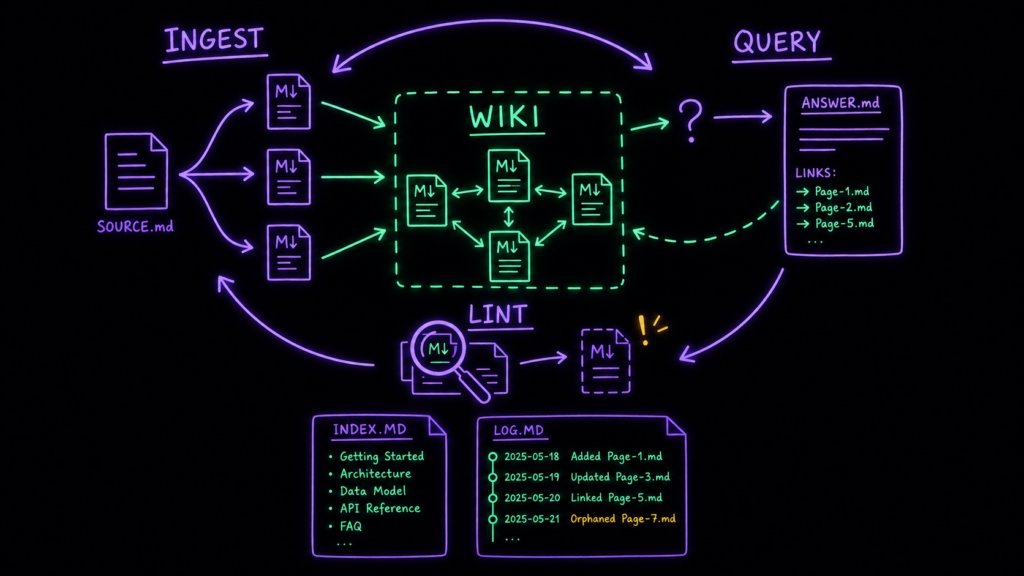
Дальше — три операции.
Ingest: кладёшь источник, модель читает, обсуждает с тобой суть, пишет страницу-сводку, обновляет индекс и связанные страницы, дописывает строчку в журнал. Один источник может задеть 10–15 страниц.
Query: задаёшь вопрос к вики, модель находит нужные страницы и собирает ответ со ссылками — а хороший ответ можно тут же положить обратно в вики отдельной страницей, чтобы находка не утонула в истории чата.
Lint: периодически просишь проверить здоровье базы — поискать противоречия, устаревшие утверждения, страницы-сироты без входящих ссылок, недостающие кросс-ссылки.
Чтобы во всём этом ориентироваться, помогают два служебных файла.
index.md — каталог: что вообще есть в вики, каждая страница с одной строкой описания. Модель читает его первым, когда ищет, где ответ.
log.md — хронология: что и когда происходило, append-only журнал.
Если каждую запись начинать одинаково (## [2026-04-02] ingest | Заголовок), журнал парсится простым grep — и ты, и модель видите, что делалось недавно.
Почему это вообще работает
Тут есть честный вопрос: личные вики люди заводили всегда — и почти всегда забрасывали. Почему сейчас должно быть иначе?
Карпатый отвечает точно: тяжёлая часть ведения базы — не чтение и не размышление, а бухгалтерия связей. Обновлять кросс-ссылки, держать сводки в актуальном состоянии, отмечать, где новые данные спорят со старыми, поддерживать согласованность между десятками страниц. Люди бросают вики потому, что стоимость поддержки растёт быстрее пользы. А LLM «не устаёт, не забывает обновить перекрёстную ссылку и трогает 15 файлов за один проход». Вики держится не потому, что мы стали дисциплинированнее, а потому что стоимость поддержки упала почти до нуля.
У идеи, кстати, длинная родословная. Ещё в 1945-м Ванневар Буш описал Memex — личное хранилище знаний, где связи между документами ценны не меньше самих документов. Единственное, что Буш не смог решить, — кто будет вести все эти связи руками. Спустя восемьдесят лет ответ нашёлся: эту работу берёт на себя модель.
Что выпустил Google: Open Knowledge Format
Пока это была идея и куча несовместимых самоделок. Вики Карпатого, вики твоей команды и экспорт каталога от вендора могут выглядеть похоже — markdown, frontmatter, кросс-ссылки, — но ни одна не задумана так, чтобы работать с другими. Нет договорённости, какие поля несёт каждый документ и что значат имена файлов. Знание остаётся запертым внутри команды, которая его собрала.
Вот этот зазор и закрывает Open Knowledge Format (OKF) — открытая спецификация, которая формализует паттерн LLM-вики в переносимый формат. Её и выпустил Google.
Формат, а не платформа
Это, на мой взгляд, главное, что стоит унести из новости. OKF — не ещё один сервис, не каталог, не SDK. Это формат. Способ записать знание так, чтобы:
- его мог произвести кто угодно — без SDK;
- его мог прочитать кто угодно — без интеграции;
- оно переживало переезд между системами, командами и инструментами;
- оно лежало в системе контроля версий рядом с кодом, который описывает;
- оно читалось и человеком, и агентом — один и тот же файл, без слоя перевода.
Бандл OKF — это просто папка. Просто markdown — открывается в любом редакторе, рендерится на GitHub. Просто файлы — упаковываются в архив, лежат в любом git-репозитории. Просто YAML-frontmatter — для небольшого набора полей, которые нужно уметь запрашивать. Никакой привязки к вендору: ценность формата — в том, сколько сторон на нём говорят, а не в том, кто им владеет.
Как устроен бандл
Каждый концепт — это один файл, а путь к файлу = идентичность концепта. Концептом может быть что угодно: таблица, датасет, метрика, плейбук, runbook, API.
sales/
├── index.md
├── datasets/
│ └── orders_db.md
├── tables/
│ ├── orders.md
│ └── customers.md
└── metrics/
└── weekly_active_users.mdВнутри файла — небольшой блок YAML-frontmatter для структурированных полей и markdown-тело для всего остального:
---
type: BigQuery Table
title: Orders
description: One row per completed customer order.
resource: https://console.cloud.google.com/bigquery?...
tags: [sales, revenue]
timestamp: 2026-05-28T14:30:00Z
---
# Schema
| Column | Type | Description |
|---------------|--------|------------------------------------------|
| `order_id` | STRING | Globally unique order identifier. |
| `customer_id` | STRING | FK to [customers](/tables/customers.md). |Концепты ссылаются друг на друга обычными markdown-ссылками — и папка превращается в граф связей, который богаче простой иерархии «родитель — ребёнок».
Три принципа держат всю конструкцию: формат минимально диктует (обязательно ровно одно поле — type, остальное на усмотрение автора); разводит того, кто пишет, и того, кто читает (человек написал — агент прочитал, один LLM сгенерировал — другой запросил); и остаётся форматом, а не платформой — не привязан ни к облаку, ни к провайдеру модели.
Что в комплекте
Чтобы формат не остался бумажкой, Google выложил эталонные реализации для обоих концов цепочки — и для того, кто OKF производит, и для того, кто его читает:
- агент-сборщик (в репозитории — enrichment agent) — обходит датасет BigQuery, пишет черновик OKF-документа на каждую таблицу и представление, а вторым проходом дополняет черновик схемами, ссылками и связями между таблицами;
- статический HTML-визуализатор — превращает любой бандл в интерактивный граф одним самодостаточным файлом: без бэкенда, без установки, данные не покидают страницу;
- три готовых бандла (GA4 e-commerce, Stack Overflow, публичные данные по Bitcoin) — собраны тем самым агентом и лежат в репозитории как живые образцы.
Сам Google честно называет это пробой концепции (proof of concept): агент — лишь один способ производить OKF, визуализатор — лишь один способ его читать; ничто в формате не требует именно их.
Зачем это на практике
Это боль не только аналитика — так же между проектами прыгают маркетологи и продакты, у каждого свой набор клиентов/заказчиков, метрик и договорённостей. Возьму пример из аналитики. Когда агент пытается ответить «как у нас считается конверсия воронки на основе потока событий», ему приходится собирать ответ из несовместимых мест: схема таблицы — в одном каталоге, смысл метрики и структура воронки — в чьей-то голове, документация по всем событиям и их работе — в корпоративной вики (и то если повезет), а то, как таблицы связаны между собой, — в комментариях к коду. В агентстве это умножается на число клиентов: у каждого свой зоопарк.
К тому, что описывает OKF, я пришёл раньше самого OKF — просто собрал руками. На проектах метаданные таблиц, определения метрик, правила разметки и join-пути лежат отдельными markdown-концептами в репозитории. Что считается «переходом в аптеку», какие модели атрибуции в ходу, как разложены выгрузки счётчика — не в голове и не в переписке, а в файлах, которые агент читает перед тем, как писать SQL. Спросишь модель холодную, без этого слоя — получишь правдоподобный шаблон «как обычно у всех», мимо нашей реальности. С базой знаний под боком — ответ в нашей логике.
Живьём этот подход я показывал на своём докладе на AHA 2026 — запись теперь доступна участникам: как из тех же трёх слоёв собирается AI-first рабочее пространство и как на нём считается, например, атрибуция.
И здесь проходит граница, вокруг которой всё это и строится. Рынок едет от prompt engineering к context engineering: проектируешь не красивую фразу, а среду, в которой модель получает нужные данные, правила и обратную связь. База знаний из markdown — это и есть RAG-слой такой среды, только живущий прямо в файловой системе. А раз так — контекст становится новым moat.
Moat (от англ. moat — ров вокруг замка) — это устойчивое преимущество, которое конкуренту не скопировать.
Сами модели публичны, промпты копируются за секунду — а ваши определения метрик, устоявшиеся правила расчёта и история принятых решений уникальны и накапливаются именно у тебя. OKF и важен как стандарт на этот слой: он делает контекст отчуждаемым — его можно передать другому человеку, другому агенту, другой команде без слоя перевода.
Где не обольщаться
Идея рабочая — но восторг лучше попридержать. Четыре вещи держу в голове.
Это v.0.1. Формат сырой, и Google прямо предупреждает: он ещё будет меняться. Строить на нём как на застывшем стандарте рано — а собрать первую вики на своих данных уже можно, это дёшево.
Демо — не твой датасет. Аккуратный граф из трёх образцовых бандлов собран на чистых публичных данных. Как агент-сборщик разберётся с вашими легаси-таблицами и кривой историей — покажет только прогон у тебя, а не чужая витрина.
Персональные данные — отдельно. Для медицины и фармы это сразу зона 152-ФЗ. В markdown-концепты идёт описание структуры и логики расчётов, но не сами данные; где и как они хранятся — решаешь до того, как агент получит доступ.
Мусор на входе — мусор на выходе. Модель аккуратно разложит по файлам что угодно, включая чушь. Что считать истиной и какие источники вообще пускать в базу — остаётся на тебе, это не делегируется.
Что унести и с чего начать
Если совсем коротко: идея базы знаний, которую AI ведёт сам, дозрела от самоделок энтузиастов до открытого стандарта — и это хороший момент попробовать её на своих задачах. Формат специально сделан так, чтобы порог был низким:
- прочитать спецификацию — она реально короткая, лежит на GitHub;
- скопировать гист Карпатого прямо в своего агента (Claude Code, Codex) — и собрать первую вики в диалоге, под свой домен;
- начать с малого: одна папка,
AGENTS.mdс правилами,index.mdиlog.md— без платформы, без SDK, просто markdown.
А дальше эта папка перестаёт быть свалкой и становится тем самым моатом. Как из такого слоя собирается полноценное AI-first рабочее пространство — со своими правилами, агентами и оркестрацией моделей под задачи — я разбираю в том самом докладе с AHA; подробный текстовый разбор будет отдельным материалом.
А вы что уже собирали в подобную базу — заметки, переписку, рабочие документы? Давайте сверимся в комментариях у меня в канале 👇
Полезные ссылки
- LLM Wiki gist (Andrej Karpathy) — первоисточник паттерна
- gist.github.com
- How the Open Knowledge Format can improve data sharing — анонс OKF
- cloud.google.com
- Мой доклад «AI-first workspace для аналитика», AHA 2026 (запись для участников)
- lms.matemarketing.ru
- Vannevar Bush. As We May Think (1945) — концепция Memex
- ru.wikipedia.org