9 июня Anthropic выпустили Claude Fable 5 — по их словам, самую способную модель, которую они когда-либо открывали для общего доступа. Одновременно запущена Mythos 5 — те же веса со снятой частью ограничений, но только для узкого круга.
Сразу оговорюсь про угол: я смотрю на это не глазами ML-инженера, а как аналитик, AI-энтузиаст и человек, который строит себе AI-first рабочее пространство. Вендорские бенчмарки беру с поправкой — «лучшая почти везде» в день выхода пишут все. Поэтому ниже не только то, что заявил сам Anthropic, но и что говорят первые независимые обзоры — а они расходятся.
Что выпустили
Fable 5 — модель нового класса, который Anthropic называют «Mythos-class». По их замерам, она показывает лучшие результаты почти на всех тестах: разработка, аналитика, компьютерное зрение, научные исследования.
Важнее самих цифр — характер преимущества: чем длиннее и сложнее задача, тем больше отрыв Fable 5 от прошлых моделей. На разовых коротких запросах разница не так заметна, а вот на долгих автономных задачах — где модель работает сама и не теряет нить — она и проявляется.
Fable 5 и Mythos 5 — это одни и те же веса, разведённые только предохранителями: Fable открыта всем, Mythos — для доверенных партнёров. Fable доступна в Claude на всех платных подписках, в Claude Code и по API; если в Claude Code она не появилась — помогает claude update.
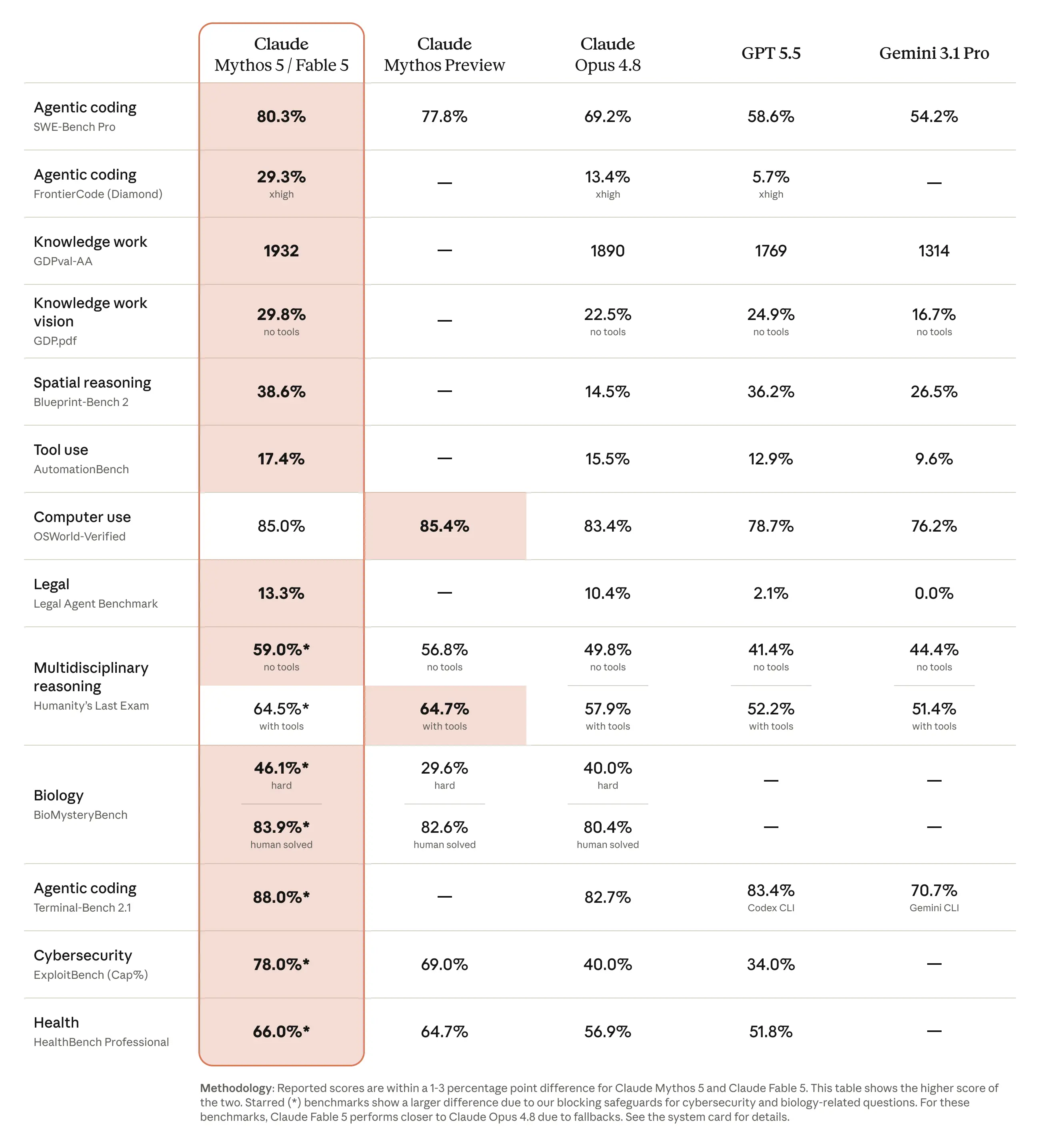
Где модель сильнее всего — по версии Anthropic
В анонсе разобрано несколько направлений. Пройдусь по тем, что ближе к рабочим задачам.
Разработка. На раннем тестировании Stripe провели на Fable 5 миграцию по всей кодовой базе на Ruby в 50 млн строк за день — команде вручную это заняло бы больше двух месяцев. При этом модель экономнее по токенам, чем прошлые: на оценке FrontierCode от Cognition (проверяет, проходит ли модель сложные задачи, удерживая планку боевого кода) Fable 5 — лучшая среди передовых моделей даже на среднем уровне усилий.
Аналитика и работа с документами. На Finance Benchmark от Hebbia (рассуждение экспертного уровня) у Fable 5 — высший балл, с заметным приростом в работе с документами, чтении графиков и таблиц. Трейдинговая компания IMC отметила, что модель почти повсеместно прошла их оценки по торговому анализу — от поиска фактов до причинно-следственного разбора.
Зрение. Заявлена как новый лидер по работе с изображениями: вытаскивает точные числа из плотных научных графиков и умеет, например, восстановить исходный код веб-приложения по одним скриншотам. Показательная деталь — Fable 5 прошла Pokémon FireRed на одних сырых скриншотах, без карт и навигационных подсказок. Прошлым моделям для этого нужны были вспомогательные инструменты и подсказки.
Память и длинный контекст. Модель удерживает фокус на дистанции в миллионы токенов и дотягивает свои ответы по собственным заметкам. На игре Slay the Spire доступ к файловой памяти поднял её результат втрое сильнее, чем у Opus 4.8 — и до финального акта она доходила втрое чаще. Принцип важнее игры: агент, который ведёт заметки и сам себя дотягивает по ходу длинной задачи.
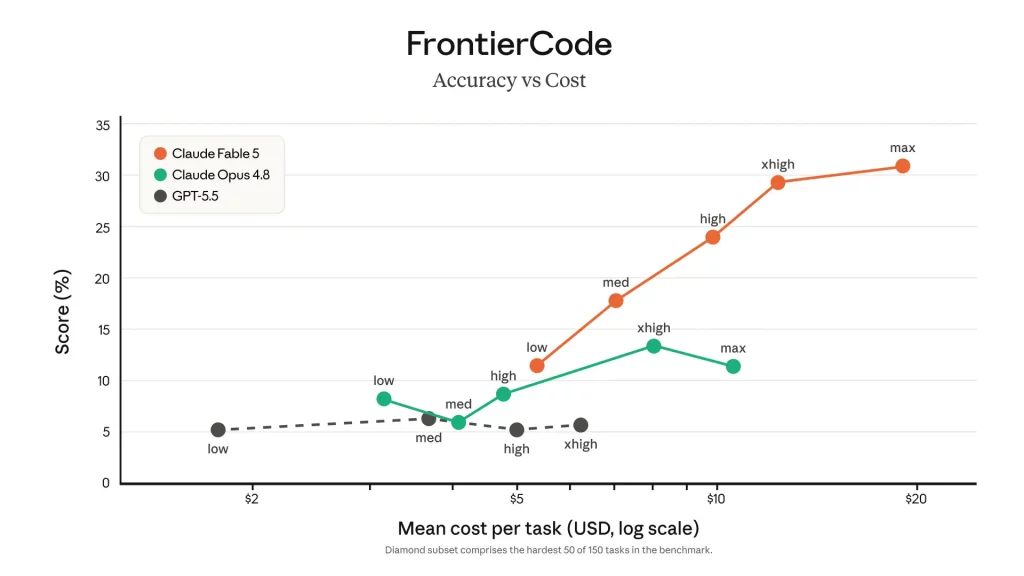
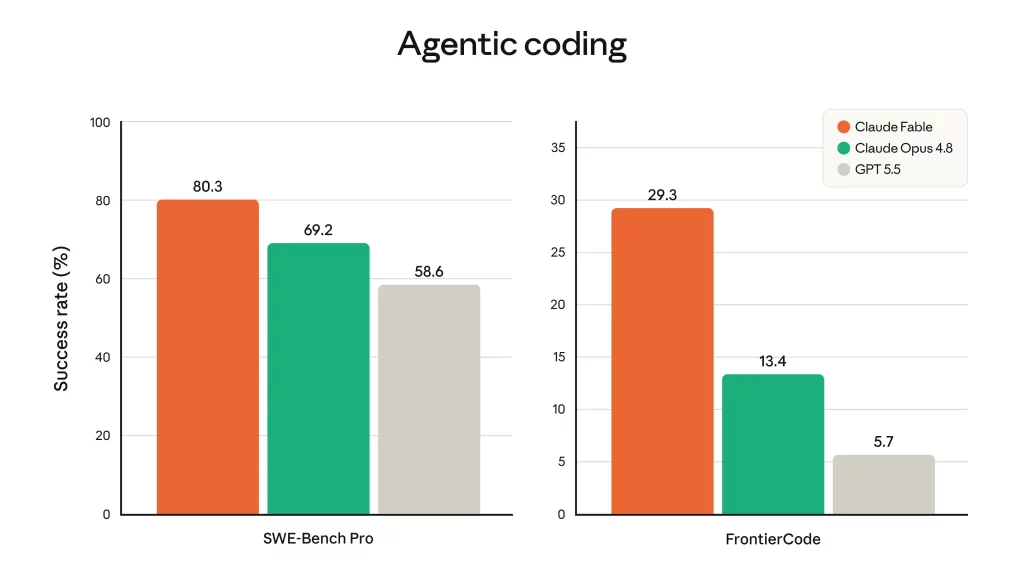
Что говорят первые независимые обзоры
Несколько команд получили ранний доступ за несколько дней до выхода. Вот их живые впечатления.
Every (доступ за 5 дней) называют Fable 5 «warp-двигателем для кода»: амбициозные вещи делает одним запросом, но на коротких понятных задачах выходит дорого и медленно — скачок виден на больших автономных сборках, а не на рутине. На их внутреннем инженерном тесте Fable набрала 91 из 100 против 63 у Opus 4.8 и 62 у GPT-5.5. Из конкретики: с одного запроса и без доступа к исходному коду модель за ≈3 часа собрала клон их собственного продукта — совместного редактора документов Proof. В другом тесте она сама сняла скриншоты своей работы в десктопной и мобильной версии, нашла визуальные дефекты и починила их — самопроверка встроилась в рабочий цикл без отдельной просьбы. Ещё наблюдение: чинит корневую причину, а не симптом. И парадокс — готовые навыки иногда мешают: презентацию Fable делает лучше, когда ей запрещают пользоваться встроенным навыком и просто дают гайд по бренду.
Ethan Mollick описывает работу с моделью как «среднее между восхищением и тревогой». Его метафора: раньше он чувствовал себя волшебником, который правит процессом, теперь — заказчиком, который поручает результат («я больше не управляю — я заказываю»). Конкретика: модель 9,5 часа подряд работала над одним инструментом — сначала выдала 19-страничный проектный документ, потом исполнила его; построила карту времени в пути, перелопатив 2200+ авиарейсов и расписания поездов; по ходу сама запускала более дешёвые экземпляры Sonnet для параллельного сбора данных. Обратная сторона — предохранители «срабатывают слишком часто» на всём, что граничит с безопасностью, а ход рассуждений модели не виден: «детали её решений мне не показывают».
Claire Vo (подкаст How I AI) — холодный душ на фоне восторгов: на бенчмарках модель «разносит» (особенно SWE-bench Pro), но в исполнении консервативна — задачу понимает, а с решительным действием медлит. По её опыту Fable сильнее всего в планировании и проектировании архитектуры, а не в режиме «бери и делай».
Расхождение показательное — «прорыв» у одних и «слишком осторожна» у других. Такое говорит больше, чем единодушные пятёрки по бенчмаркам.
Сколько стоит и когда оправдано
Fable 5 и Mythos 5 стоят $10 за миллион токенов на входе и $50 — на выходе. Это вдвое дороже Opus 4.8, но при этом вдвое дешевле прежнего Mythos Preview.
Нюанс, который многих расстроил: в подписках Fable включена до 22 июня, дальше — по кредитам. Судя по всему, после этого у подписки будет API-баланс, равный её цене (скажем, $100), а сверх него токены пойдут уже за отдельную плату. Anthropic пишут, что могут вернуть модель в подписку позже, если найдут достаточно мощностей.
Практический критерий совпадает у вендора и у обзоров: Fable заточена под долгие автономные задачи — «может работать днями, и чем длиннее задача, тем больше отрыв». На коротких правках разницы с Opus 4.8 часто не почувствуешь, а платишь вдвое. И отдельная деталь от Every: максимальный режим усилий не всегда даёт лучший результат — иногда среднего достаточно.
Предохранители и вторая модель — Mythos 5
Главная инженерная развязка здесь — как Anthropic разводят мощность и безопасность.
Fable 5 — публичная версия с предохранителями. Модель настолько способная, что её возможности при злоупотреблении могли бы навредить. Поэтому запросы по чувствительным темам — кибербезопасность, био- и химия, дистилляция моделей (копирование чужой модели через её же ответы) — она отдаёт не себе, а модели послабее, Opus 4.8, и уведомляет об этом. Срабатывает, по заявлению Anthropic, меньше чем в 5% сеансов. Но ложные срабатывания реальны: на Reddit уже жалуются на блокировки за легитимные задачи двойного назначения. Anthropic обещают снижать число ложных срабатываний по мере выхода новых моделей.
Mythos 5 — те же веса, но со снятой в ряде областей защитой. Доступна узкому кругу доверенных партнёров — специалистам по кибербезопасности и поставщикам инфраструктуры — через программу Project Glasswing совместно с правительством США (как обновление Mythos Preview). По заявлению Anthropic, это самые сильные в мире способности в кибербезопасности; позже доступ обещают расширить.
Что в сухом остатке
Набор заявленных способностей сильный, и в главном независимые тесты сходятся: скачок — на длинных автономных задачах, а не на коротких правках. А выводы по остальному придержу, пока не прогоню сам.
Мои собственные тесты пока скромные: визуально Fable работает даже быстрее (похоже, делает меньше обращений к инструментам) и внимательнее. Но задач, с которыми не справлялся бы Opus 4.8, у меня немного — так что вывод честный: надо тестить больше. А цена вдвое выше Opus заставляет считать, где это реально оправдано.
Полезные ссылки
- Анонс Anthropic: Claude Fable 5 and Mythos 5
- www.anthropic.com
- What it feels like to work with Mythos by Ethan Mollick
- www.oneusefulthing.org
- Claude Fable 5 review: what the new Mythos model gets right (and very wrong) by Claire Vo
- www.lennysnewsletter.com
- Claude Agent SDK и тарифные планы
- support.claude.com
- Ложные срабатывания (тред на Reddit)
- www.reddit.com