С AI сейчас две вещи стабильно верны. Первая — он действительно повсюду: в почте, в IDE, в рекламных кабинетах, в бытовой технике. Вторая — поле меняется так быстро, что за терминологией не успевают даже те, кто работает в сфере высоких технологий.
Я собрал семь терминов, которые стоит понимать, пока AI развивается такими темпами, и разобрал каждый простым языком. Формат — короткий справочник: чтобы можно было перечитать и освежить в памяти, а не искать определения заново.
Сразу оговорюсь: я не инженер данных и не ML-исследователь. Описываю термины так, как понял их сам — но стараюсь делать фактчек и не врать в деталях. Если где-то упростил слишком сильно — поправьте в комментариях.
Сколько из семи вы уже знаете?
Агентный AI (Agentic AI)
Пожалуй, самый затёртый термин последнего года: AI-агентов сегодня строят буквально все. Но что за ним стоит на самом деле?
AI-агент умеет рассуждать и действовать автономно, чтобы достичь цели. В этом ключевая разница с обычным чат-ботом: чат-бот отвечает на один запрос за раз, а агент работает сам, по кругу проходя несколько стадий:
→ воспринимает окружение (что вообще происходит),
→ рассуждает — прикидывает, какой следующий шаг лучший,
→ действует по плану, который сам же и построил,
→ наблюдает за результатом действия — и заходит на новый круг.
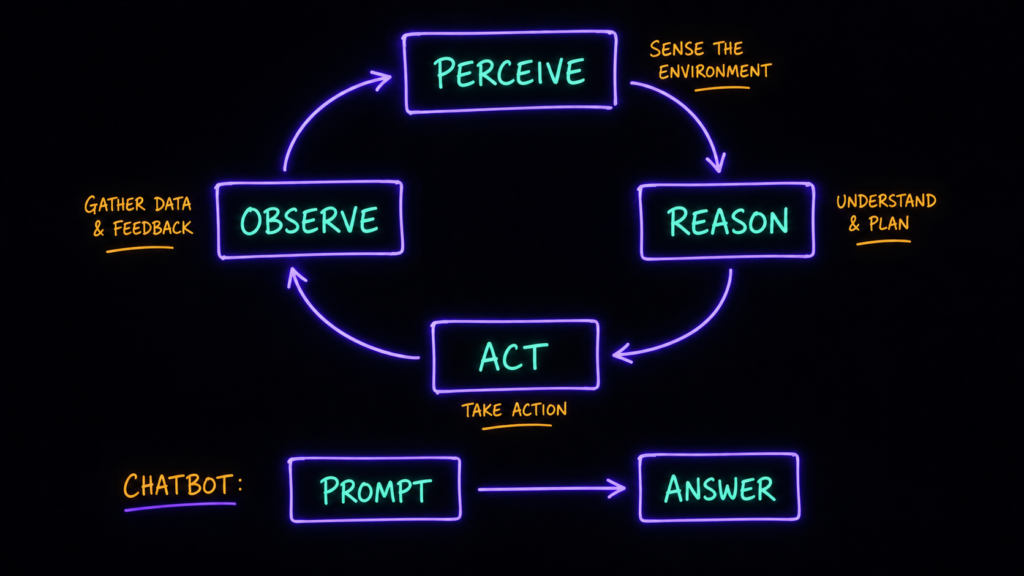
И так по спирали, пока не дойдёт до цели. Роли могут быть любые: travel-агент, который бронирует поездку; data-аналитик, который ищет тренды в квартальных отчётах; или DevOps-инженер, который ловит аномалии в логах, поднимает контейнеры под тесты фиксов и откатывает кривые деплои.
Здесь сразу включается профессиональная придирка: слово «автономно» означает, что агент принимает решения за вас. А значит, ключевой вопрос — как мы проверяем, что эти решения верны. Но измеримость агентов — тема для отдельного материала.
Большие reasoning-модели (Large Reasoning Models)
Агентов обычно строят на особой разновидности больших языковых моделей — это и есть reasoning-модели (модели рассуждения).
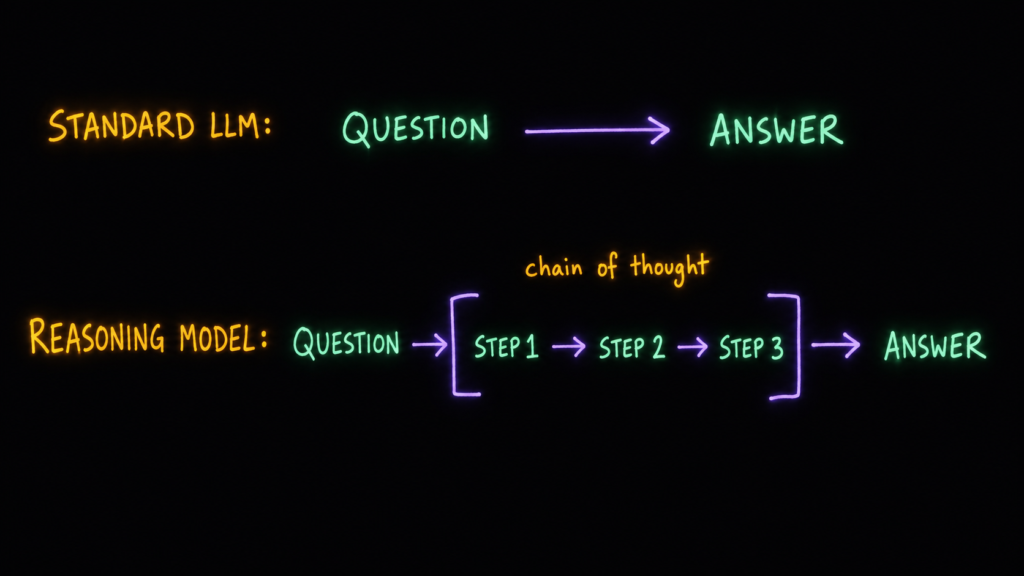
Это специализированные LLM, которые прошли дообучение с упором на рассуждение. Обычная LLM выдаёт ответ сразу. Reasoning-модель обучена идти к ответу по шагам — а это ровно то, что нужно агенту при планировании сложных многоходовых задач.
Хитрость в том, на чём её учат: на задачах с проверяемо правильным ответом — математика или код, который можно прогнать через компилятор. Через обучение с подкреплением (reinforcement learning) модель учится строить такие цепочки рассуждений, которые приводят к верному финальному ответу.
Каждый раз, когда чат-бот замирает с подписью «думает…» перед ответом — это и есть reasoning-модель за работой: она генерирует внутреннюю цепочку рассуждений (chain of thought), разбивая задачу на шаги, прежде чем что-то вам выдать.
Векторные базы данных (Vector Database)
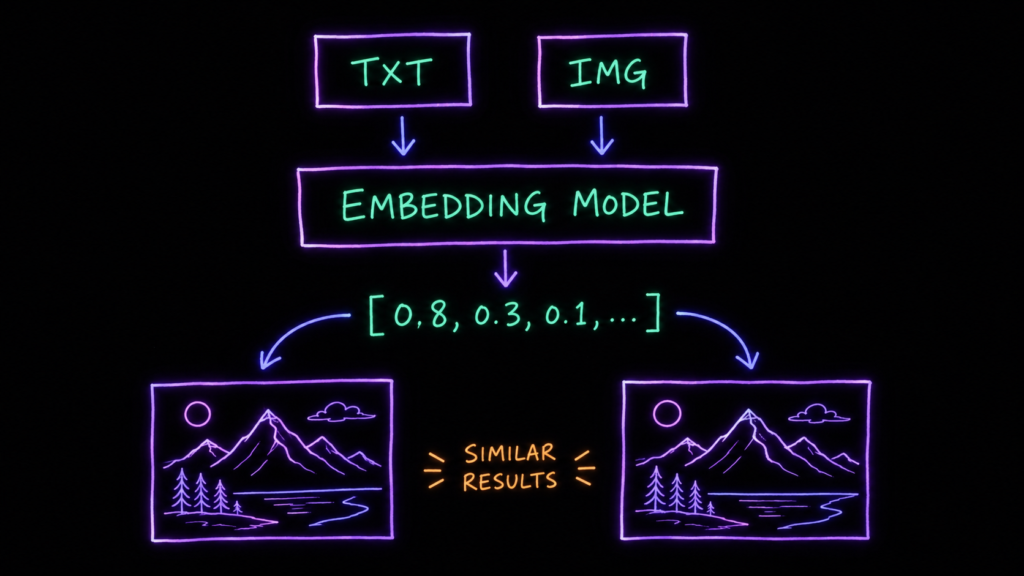
Спускаемся на уровень ниже. Обычная база хранит данные как есть — текст и картинки лежат в ней цельными файлами, так называемыми blob (binary large object). Векторная устроена иначе: вместо самого файла в неё попадает его числовое представление, а за перевод отвечает embedding-модель.
Она превращает данные — скажем, картинку — в вектор. Вектор — это, по сути, длинный список чисел. И этот список чисел захватывает смысл содержимого, его семантику.
Зачем так? Затем, что в векторной базе поиск становится математической операцией: мы ищем векторы, которые лежат близко друг к другу. А «близко в пространстве векторов» означает «похоже по смыслу».
Например: берём фотографию горного пейзажа → embedding-модель раскладывает её в многомерный числовой вектор → делаем поиск похожих, находя ближайшие векторы в этом пространстве. На выходе — похожие картинки. Ровно так же это работает с похожими статьями или, скажем, музыкой. Что закодировали — то и ищем по смыслу.
RAG (Retrieval-Augmented Generation)
Векторные базы играют большую роль в следующем термине — RAG, или генерация с дополнением через поиск.
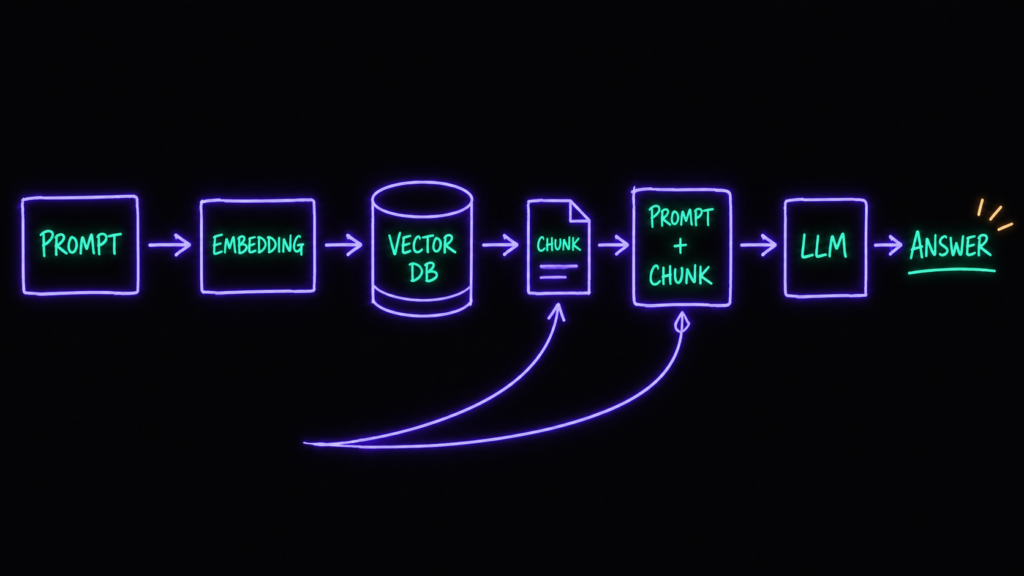
Идея простая: RAG использует векторную базу, чтобы обогатить промпт к языковой модели. По шагам:
→ компонент-ретривер берёт входной промпт пользователя,
→ превращает его в вектор через ту самую embedding-модель,
→ делает поиск похожего в векторной базе,
→ то, что нашлось, вшивается обратно в промпт к LLM.
На практике: я задаю вопрос про политику компании → RAG-система сама вытаскивает нужный раздел из корпоративного справочника и подкладывает его в промпт. Модель отвечает уже не «из головы», а опираясь на конкретный документ.
RAG мне интересен сразу с двух сторон. Во-первых, ответ можно привязать к источнику: не «модель так сказала», а «модель опирается вот на этот фрагмент документа» — это уже про проверяемость, а в неё я верю. Во-вторых, на этой же идее я строю свой рабочий процесс: вместо того чтобы каждый раз заново объяснять модели специфику проекта, держу контекст в файлах — локальная база знаний в Obsidian работает как RAG-слой, из которого агент сам подтягивает нужное. По сути это RAG поверх собственных markdown-заметок: рынок уходит от «идеального промпта» к проектированию контекста, и накопленный контекст со временем оказывается ценнее самой модели.
MCP (Model Context Protocol)
Один из самых интересных пунктов списка. Чтобы языковые модели были по-настоящему полезны, им нужно дотягиваться до внешних данных, сервисов и инструментов. MCP стандартизирует то, как приложения передают модели контекст.
Допустим, мы хотим, чтобы наша LLM умела подключаться к внешней базе данных, к репозиторию с кодом, к почтовому серверу — да к чему угодно. Раньше под каждый новый инструмент разработчик пилил отдельную, одноразовую интеграцию. MCP даёт стандартный способ дать AI доступ к вашим системам.
Механика: есть MCP-сервер — через него модель понимает, что именно нужно сделать, чтобы достучаться до конкретного инструмента. Одно стандартное соединение вместо зоопарка костылей.
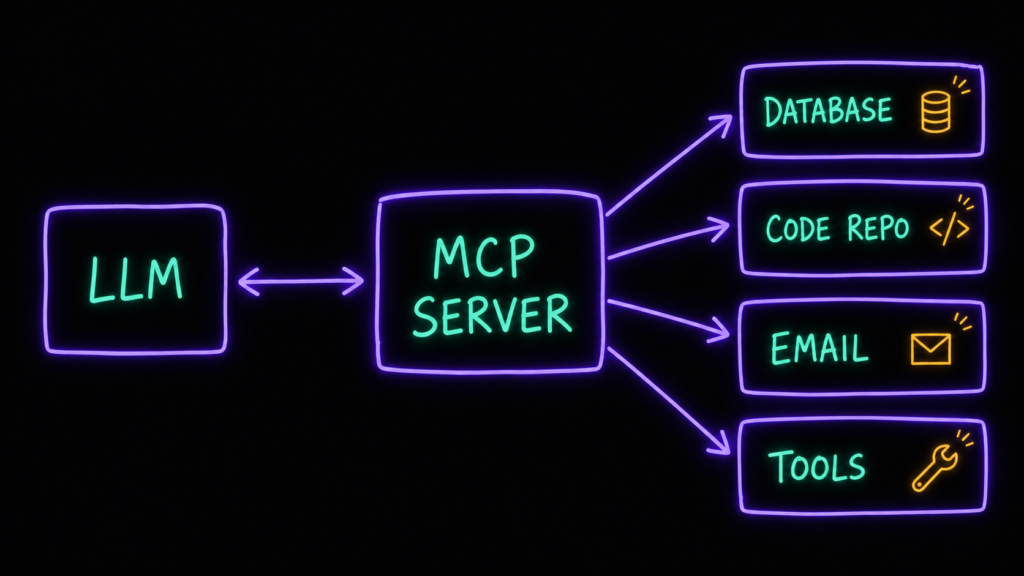
MCP — это открытый стандарт, который придумали в Anthropic, и за пару лет он стал чем-то вроде «USB-C для AI-инструментов». Аналогия не моя, но точная: один разъём вместо десятка проприетарных проводов.
MoE (Mixture of Experts, «смесь экспертов»)
Идея MoE не новая — статью опубликовали в научном журнале ещё в 1991 году. Но актуальной как сегодня она не была никогда.
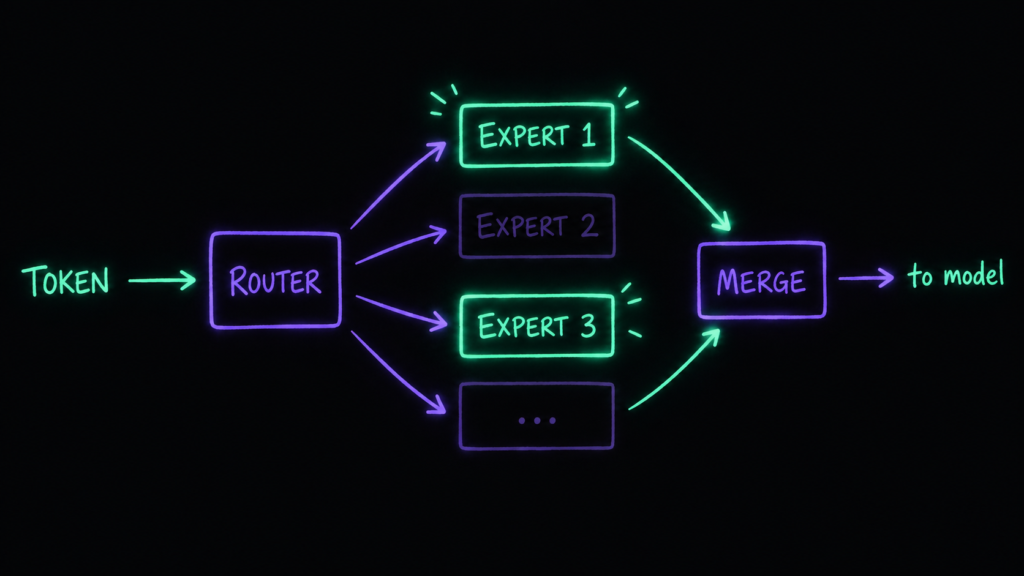
Суть: большая языковая модель делится на набор экспертов — специализированных нейронных подсетей. Их может быть и три, и сотня с лишним. Дальше работает маршрутизатор (routing): под конкретную задачу он активирует только тех экспертов, что реально нужны.
→ выбрали нужных экспертов под задачу,
→ слили (merge) их выходы математической операцией в единое представление,
→ оно идёт дальше через остальную модель.
Зачем это нужно: так можно наращивать размер модели без пропорционального роста затрат на вычисления. Так устроены современные MoE-модели: десятки экспертов, но на каждый токен активируется лишь горстка нужных. То есть в модели могут быть миллиарды параметров суммарно, а на инференсе работает только их доля.
ASI и AGI (супер- и общий интеллект)
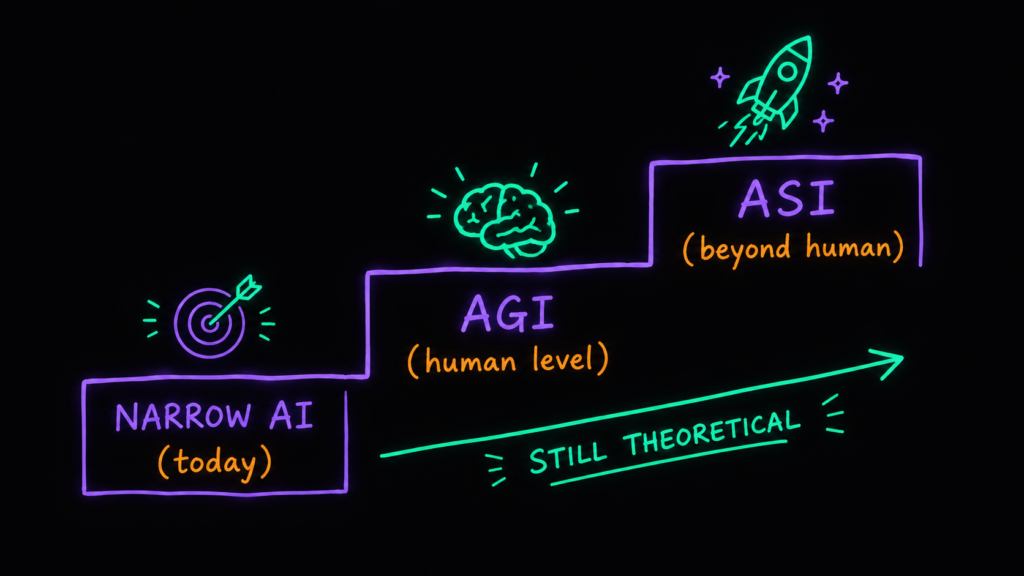
На десерт — крупный термин. ASI, artificial superintelligence, искусственный суперинтеллект. Это цель всех передовых AI-лабораторий. И на сегодня он чисто теоретический: его не существует, и неизвестно, появится ли вообще.
Чтобы понять ASI, нужен сосед по полке — AGI, artificial general intelligence, общий искусственный интеллект. К нему сегодняшние лучшие модели потихоньку приближаются. AGI тоже пока теория, но если он состоится — сможет решать все когнитивные задачи не хуже любого человека-эксперта.
ASI — на шаг дальше: система с интеллектом выше человеческого, потенциально способная к рекурсивному самоулучшению. То есть ASI мог бы переписывать и улучшать сам себя, становясь всё умнее по бесконечному кругу.
Такое развитие либо решило бы крупнейшие проблемы человечества, либо создало бы новые, которых мы пока даже представить не можем. Поэтому термин стоит держать на радаре — даже если он сегодня звучит как фантастика.
Что в итоге
Семь терминов — это не про то, чтобы блеснуть словами на созвоне. Это базовый словарь, без которого сложно говорить о том, что сейчас происходит с AI: агенты строятся на reasoning-моделях, тянут знания через RAG и векторные базы, дотягиваются до инструментов через MCP, а под капотом всё чаще крутится MoE. ASI с AGI пока стоят в стороне как горизонт.
Семь — это не предел, при желании можно набрать и семьдесят: поле огромное. А какой термин добавили бы вы? Что я зря не включил в список — пишите в комментариях, разберёмся вместе.
Полезные ссылки
- 7 AI Terms You Need to Know: Agents, RAG, ASI & More
- www.youtube.com
- Model Context Protocol
- modelcontextprotocol.io
- Adaptive Mixtures of Local Experts
- www.cs.toronto.edu