Задача исследования поискового спроса знакома каждому SEO-специалисту. Сбор и кластеризация семантики, анализ популярности (частотности) и сезонности запросов не вызывает каких-либо особых сложностей. Но что, если нужно исследовать целую сферу бизнеса, в которой представлено более 50 брендов, а сроки и ресурсы ограничены? Именно эту задачу мы и попробуем решить.
Если вы следите за активностью JetStyle (агентства, где я работаю) – то могли заметить, что мы активно исследуем автомобильный рынок. Он бурно меняется, одни бренды ушли, а на их место приходит множество других, Китайских. Подробнее про исследование и плакат, который у нас получился читайте тут.
Так вот, нам захотелось понять что происходит со спросом на автомобили различных брендов — кто упал, а кто вырос. Отсюда можно сформулировать нашу задачу.
Задача и инструментарий
Задача: Исследовать динамику спроса на автомобильные бренды в России.
Кажется, вполне себе обычная задача, знакомая каждому SEO-специалисту: собрать поисковые запросы, собрать сезонности из Яндекс Wordstat, визуализировать собранные данные.
Из задачи вытекает необходимый инструментарий:
Базовый:
- KeyCollector: с его помощью мы сможем легко и быстро собрать запросы и сезонности. К нему понадобится также аккаунт Яндекс Директ и proxy;
- Google-таблицы: в них мы можем сложить результат и там же визуализировать, создав простенькие графики;
Продвинутый:
- Python и библиотека Pandas: поможет автоматизировать некоторые рутинные задачи;
- ClickHouse: место, куда можно удобно сложить собранные данные. Можно остаться и в Google-таблицах, просто это надежнее и с заделом на будущее;
- Yandex Data Lens: Bi-инструмент от Яндекса, в котором мы сможем построить продвинутую визуализацию наших данных;
Решение
Способ 1 — решаем «В лоб»
Для начала попробуем решить задачу «в лоб». Составляем список всех автомобильных брендов, представленных на рынке. Не забываем, что нам нужны несколько вариантов названия — на английском и на русском. Обычно вариант на русском более популярен у пользователей. Помимо этого могут быть словоформы русского названия — к «европейцам» все привыкли, но с «китайцами» сложнее, один только новый китайский бренд KAIYI чего стоит.
Для этого используем логику и поисковые подсказки Яндекса, а Яндекс Вордстат используем для проверки является ли словоформа используемой пользователями.
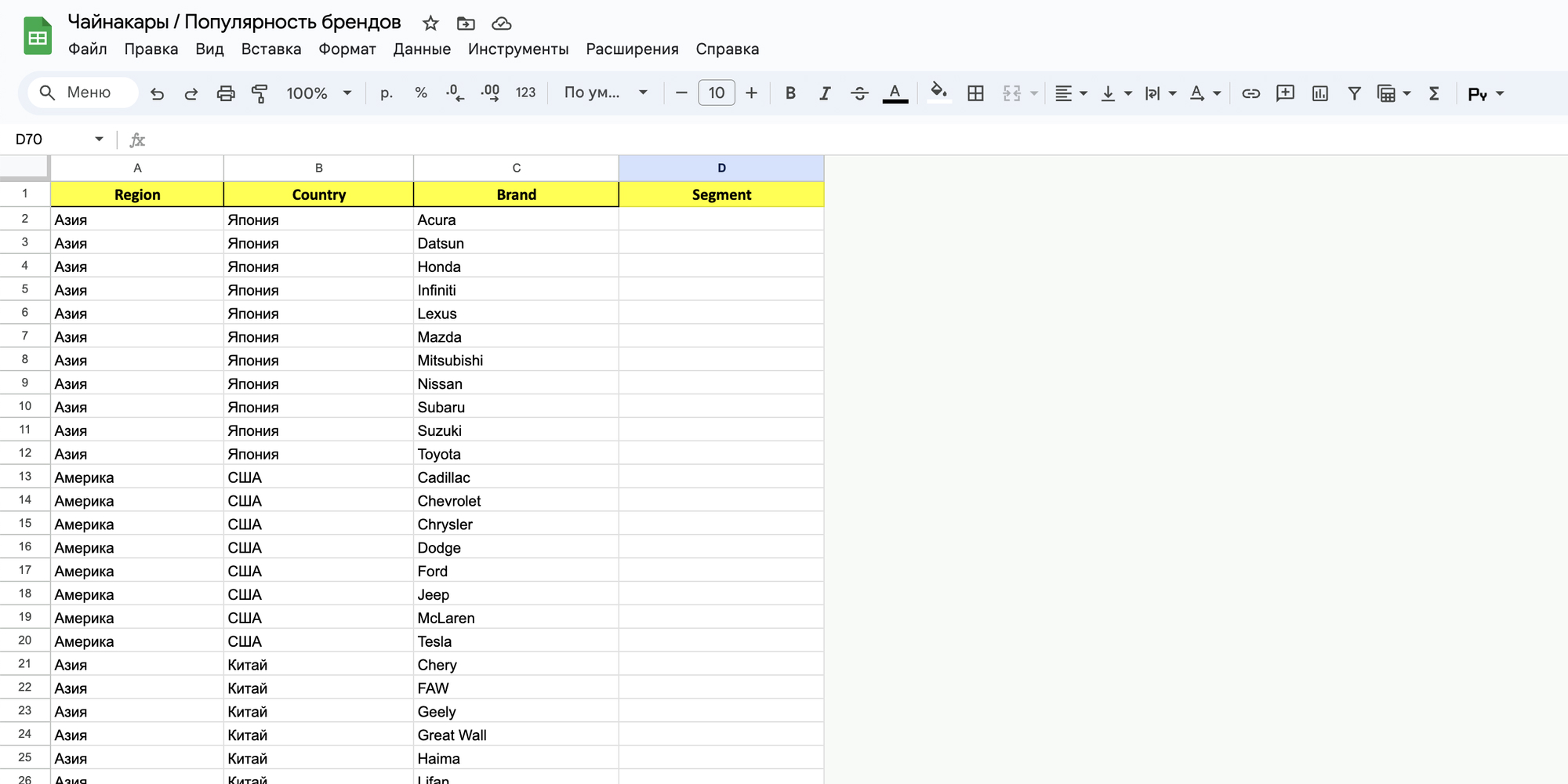
В результате получаем таблицу со списком автомобильных брендов:
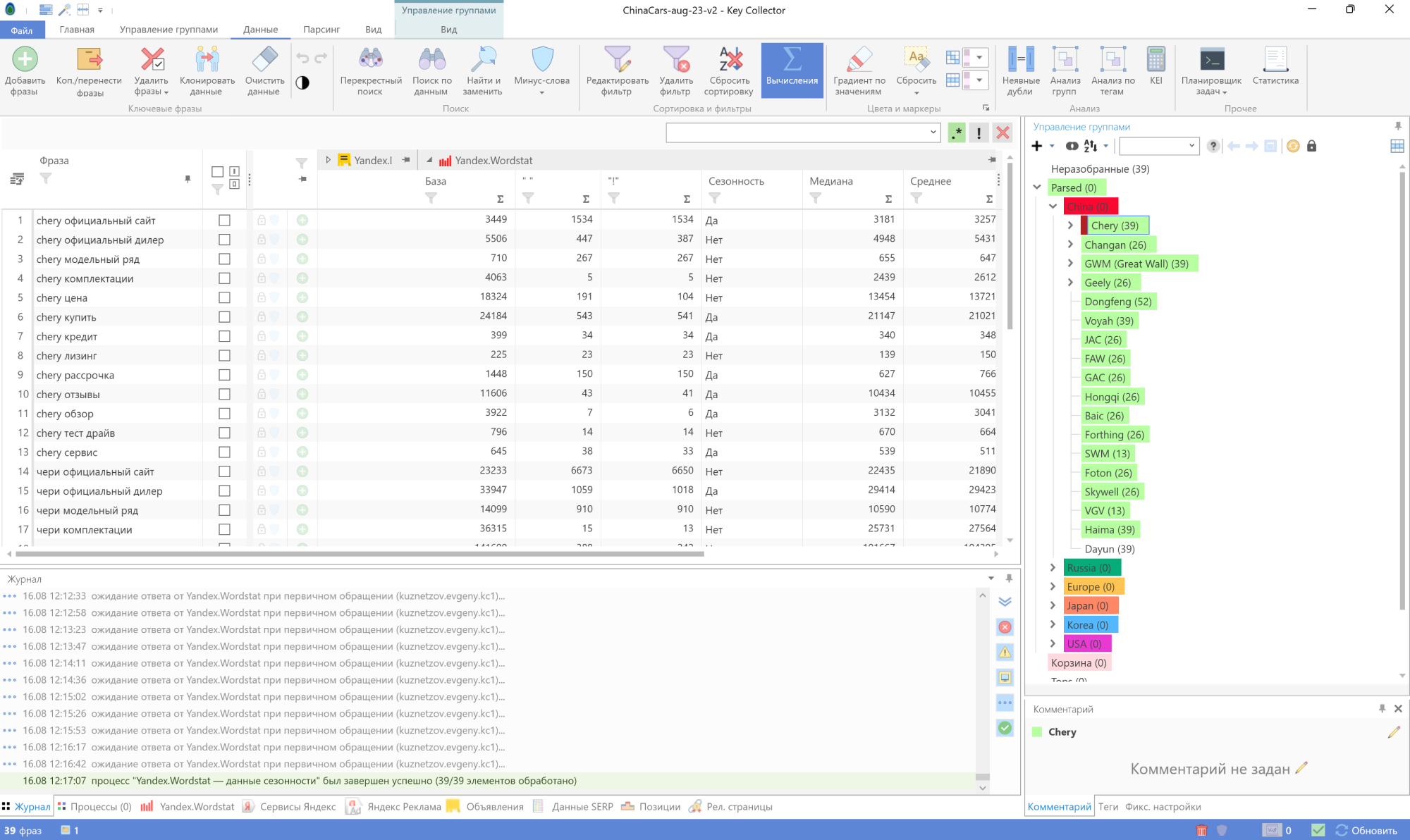
Далее загружаем наши фразы в KeyCollector и собираем сезонности по России. Описывать здесь я это не буду, есть отличное видео у Александра Ожгибесова про настройку KeyCollector:
С парсингом сезонностей там тоже ничего сложного: выбираем регион, запускаем процесс и занимаемся другими делами пока данные собираются.
Когда мы собрали сезонности — экспортируем их. На выходе KeyCollector выдает нам CSV со списком запросов и популярностью по месяцам. Загрузим его в Google Sheets. Для простой визуализации этого может оказаться достаточно, но мы немного усложним задачу в угоду функциональности.
Шаг 1. Трансформируем таблицу в вертикально-ориентированную, здесь можно сделать это и вручную т.к. данных не очень много.
Шаг 2. Обогатим данными (добавим название бренда для разных словоформ и страну бренда).

Шаг 3. Подключим Google Sheets к Yandex Data Lens для более удобного построения чартов.
Строим первый чарт и…….получаем ничего.
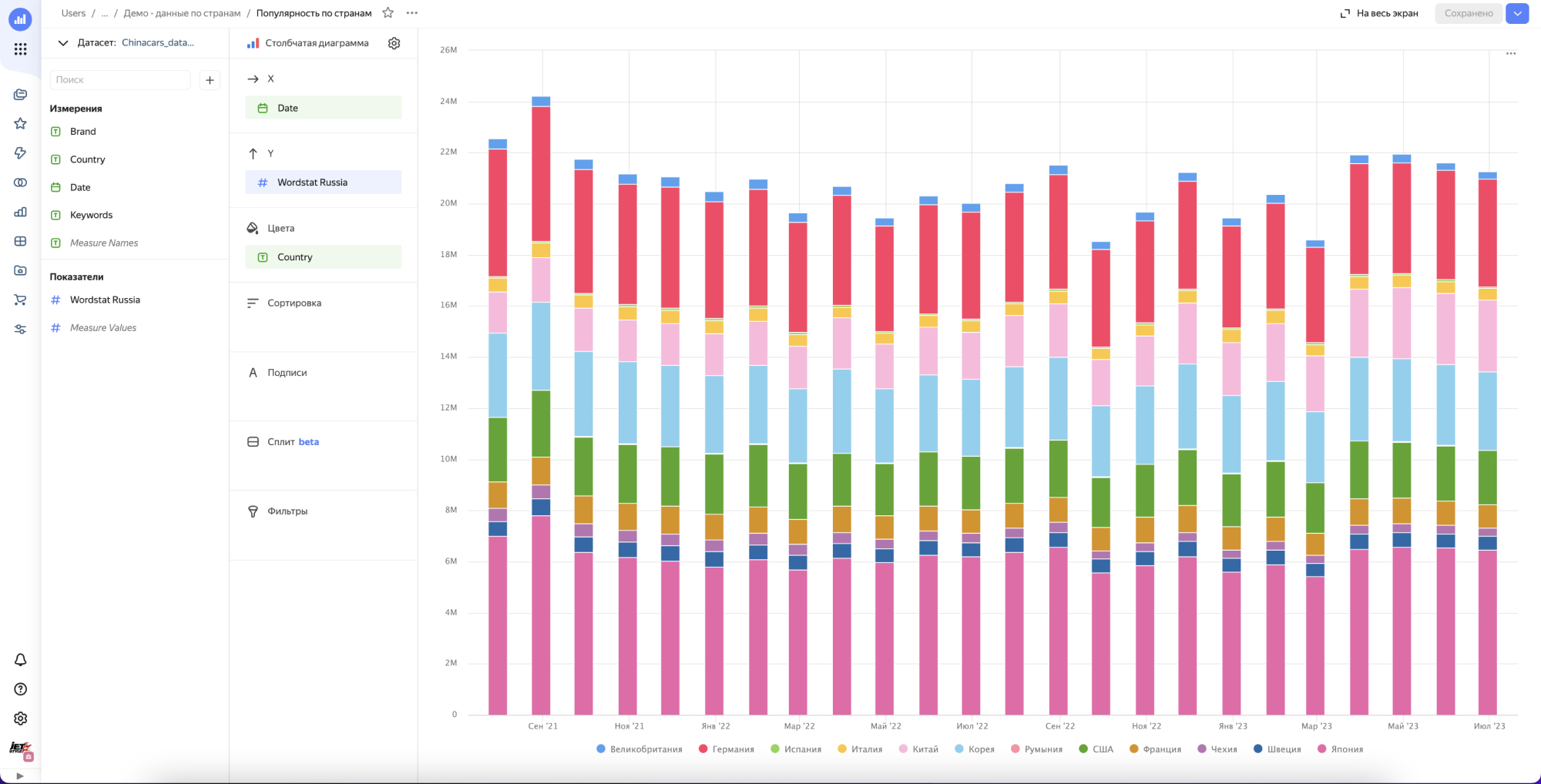
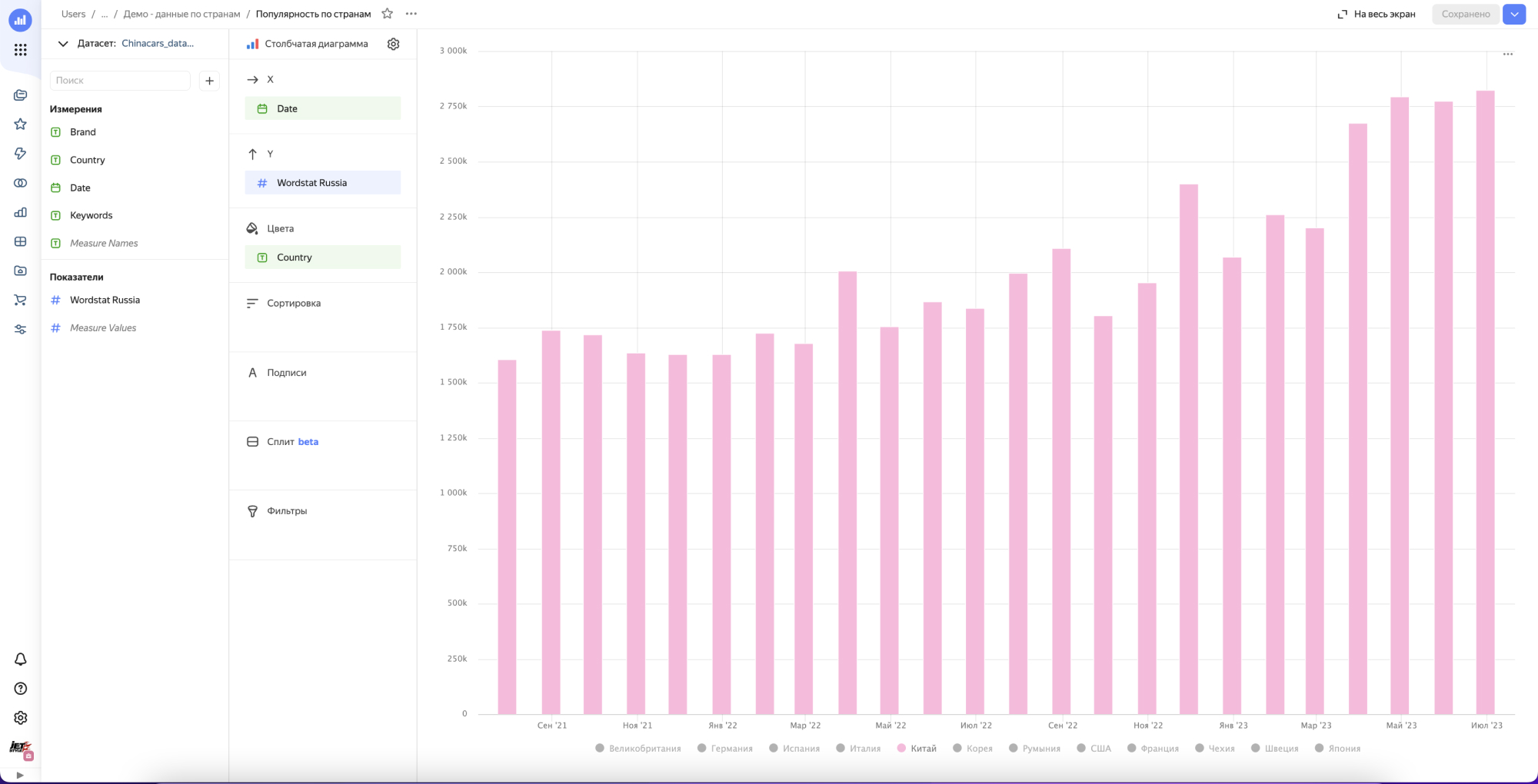
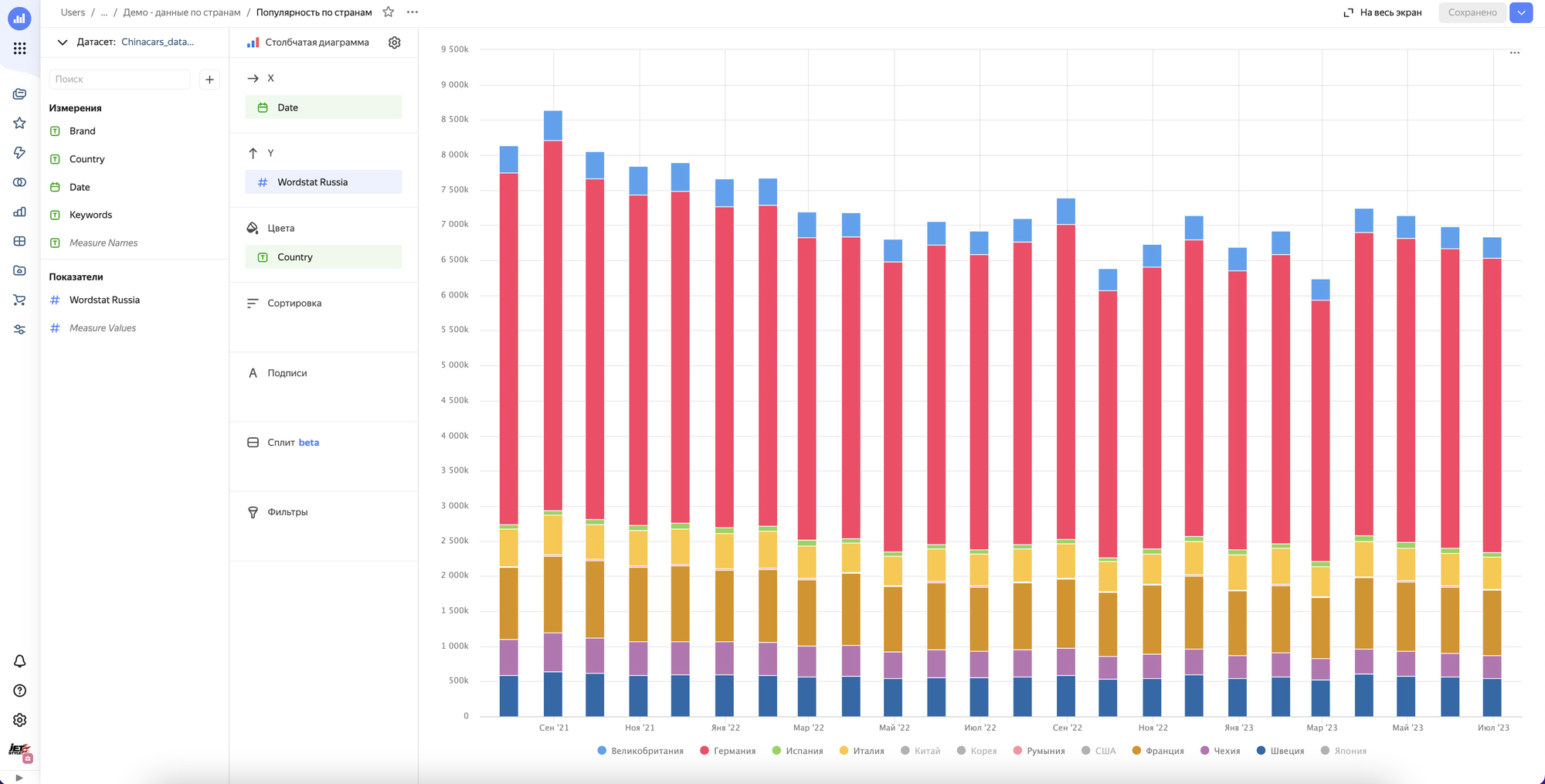
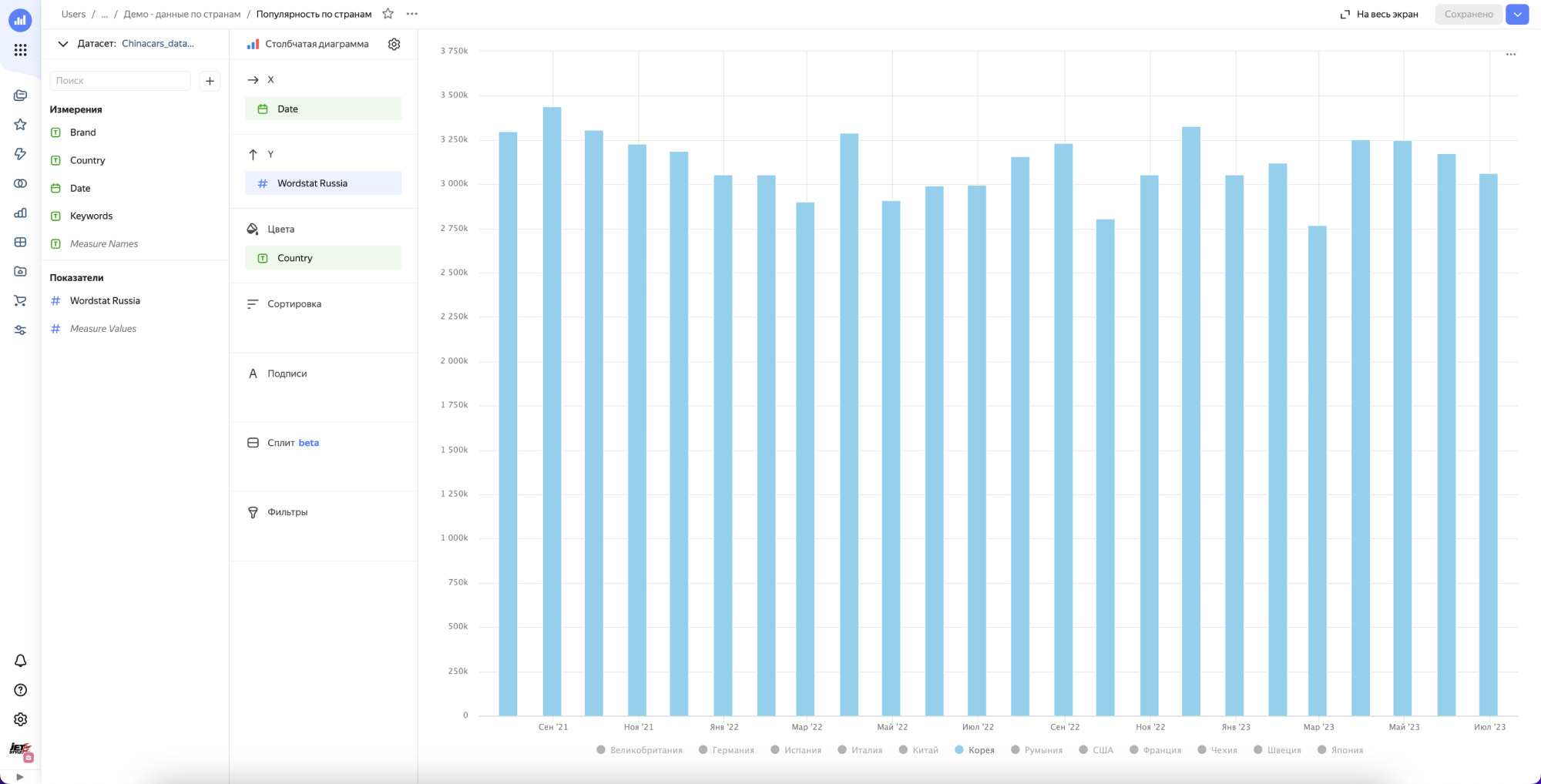
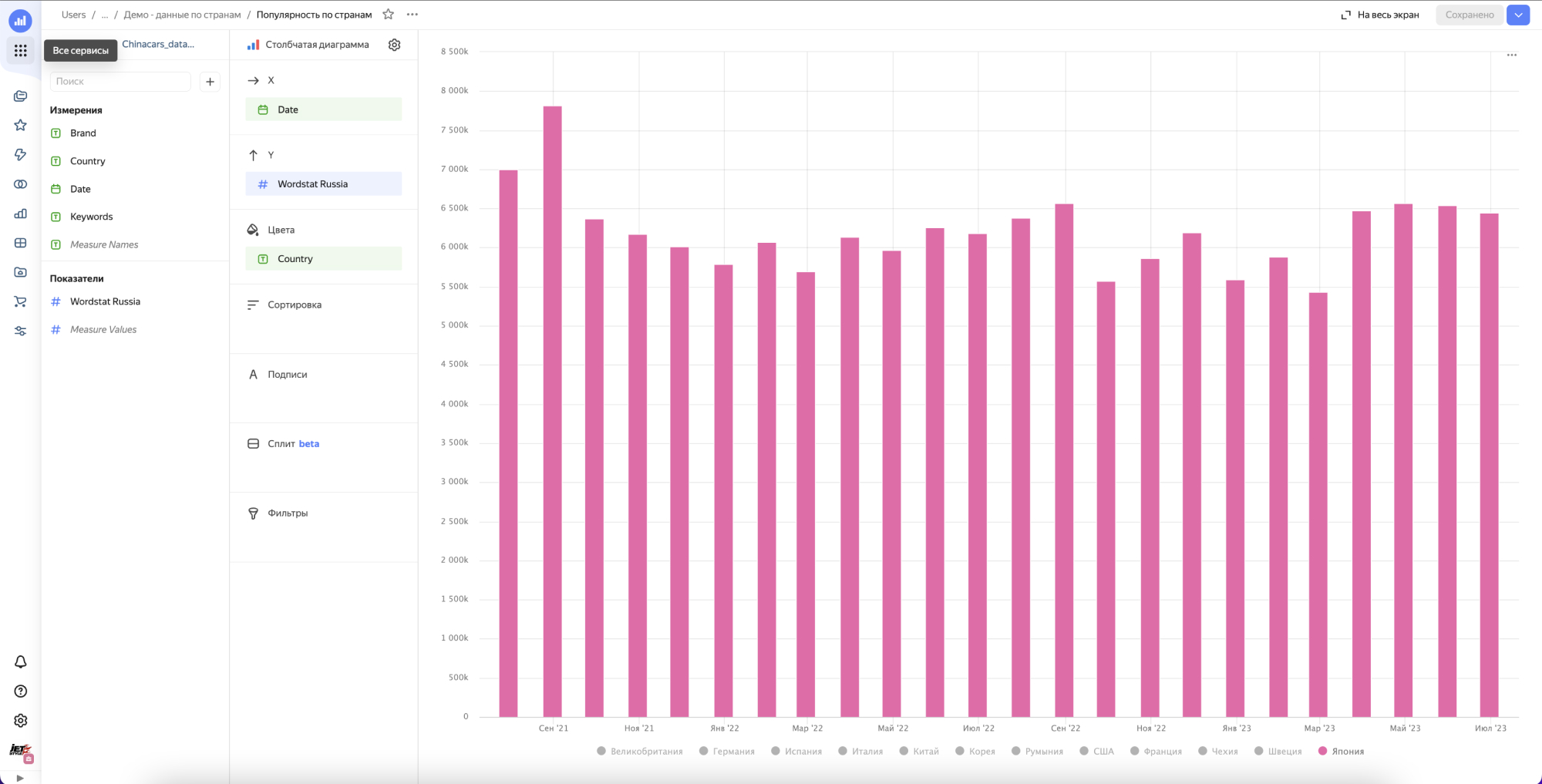
Все дело в том что в этом решении мы не учитываем интент поискового запроса, а смотрим просто все бренды в общем. В результате картина смазанная и не видно наглядно динамики по вытеснению европейцев, корейцев и японцев китайцами, хотя казалось бы она очевидна из-за того что мы видим на улицах и в рекламе.
Способ 2 – если копнуть чуть глубже
Возвращаемся на шаг сбора поисковых фраз. Вспоминаем что у нас уже есть список всех брендов. Надо добавить к ним поисковый интент. Для этого пойдем в SpyWords (он кстати доступен бесплатно, если вы используете Elama и у вас тариф оптимум) и посмотрим по каким группам фраз находятся в поиске официальные сайты нескольких брендов.
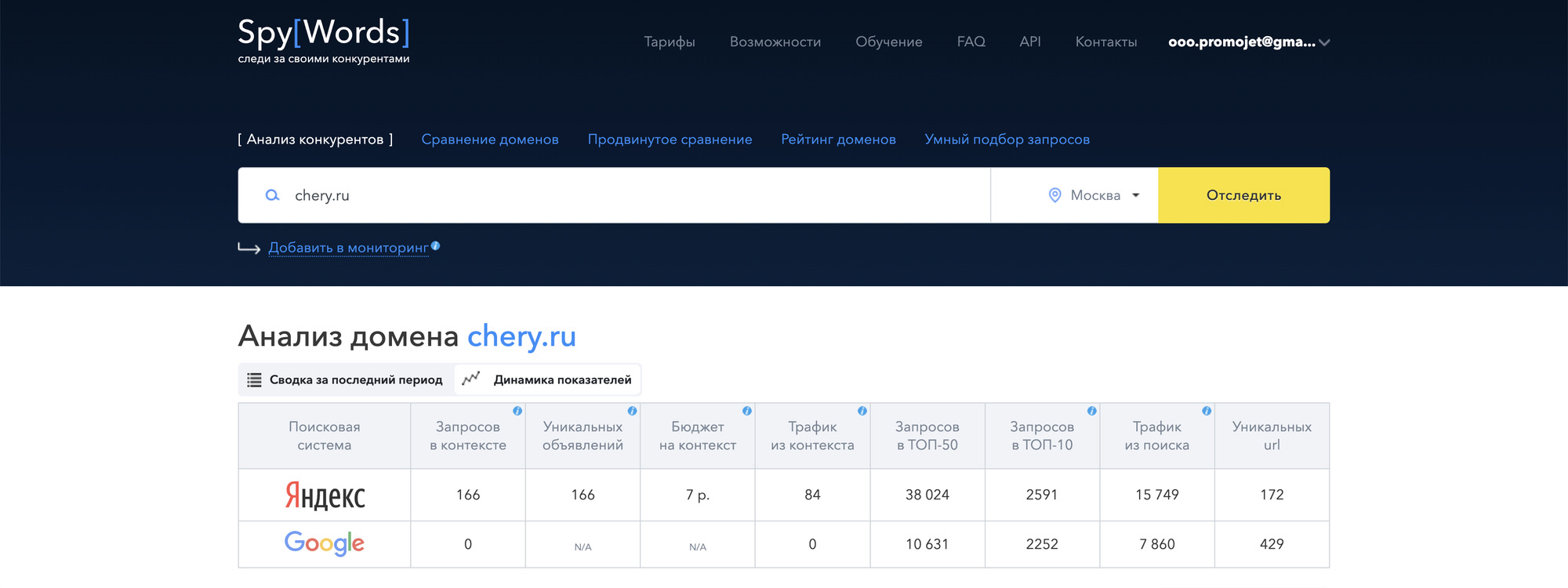
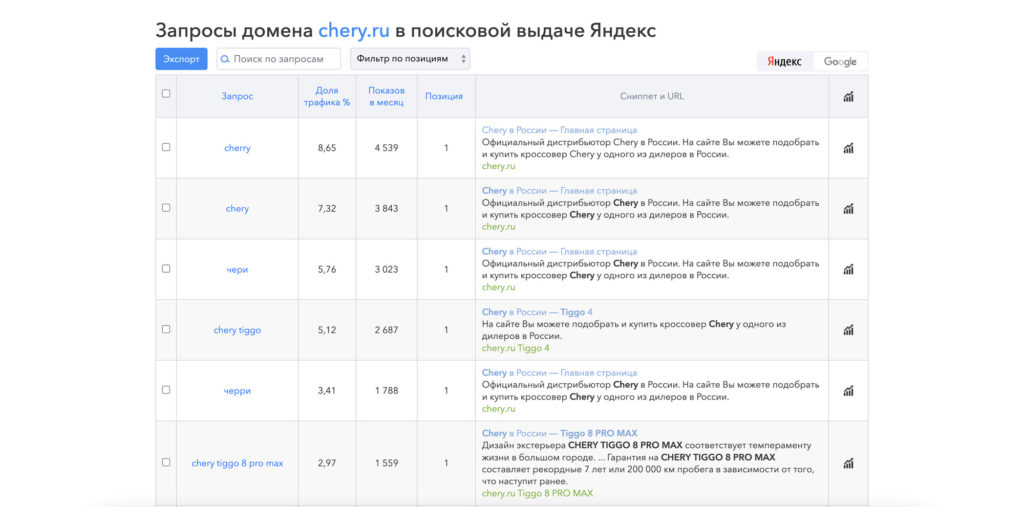
Выгрузим отчеты по этим сайтам и внимательно изучим их.
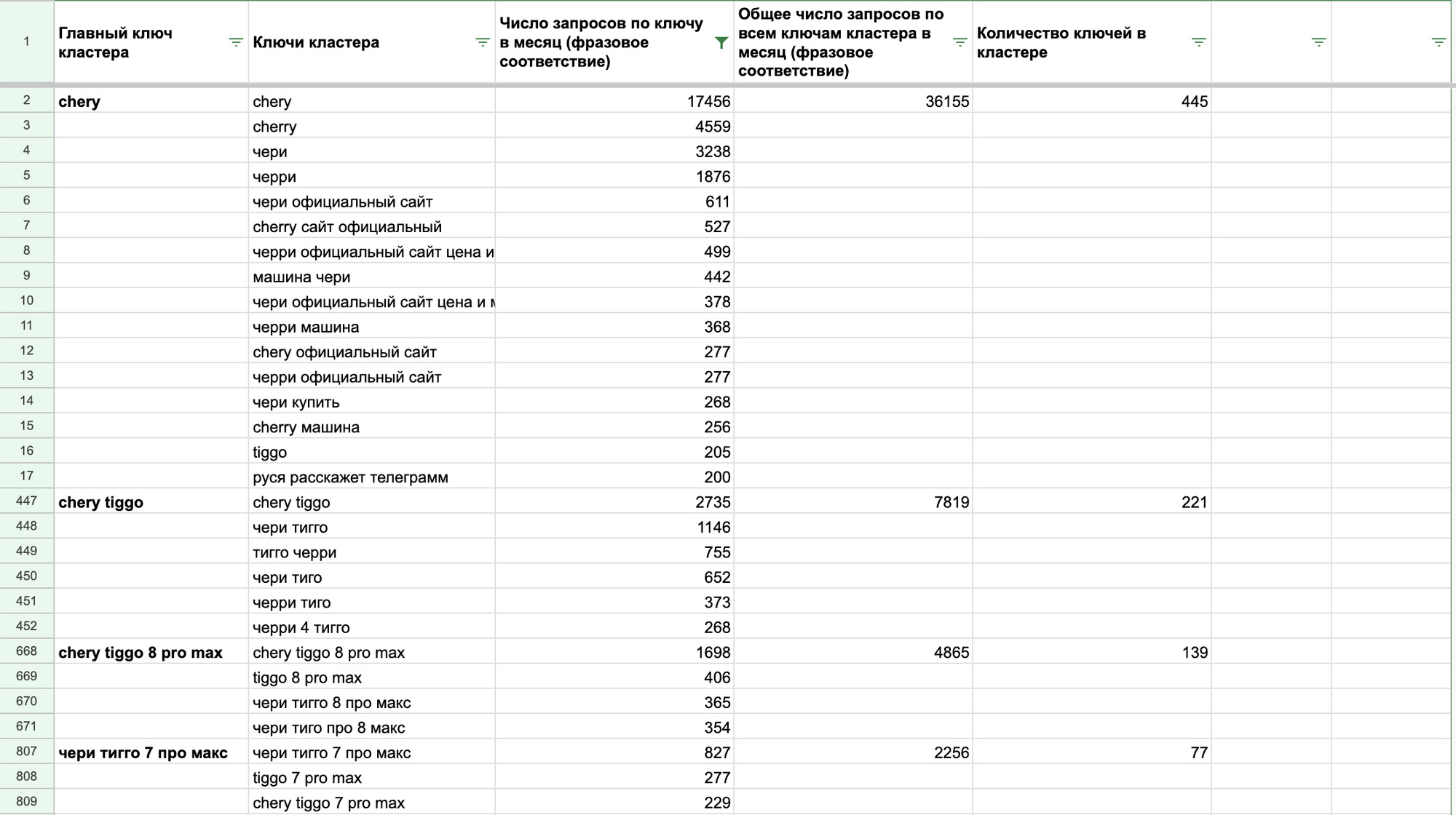
Совет: Эту же задачу можно решить выгрузив все фразы по одному бренду из Yandex Wordstat, кластеризовав их с помощью Разбиваки Алексея Кулакова и проанализировав получившиеся группы.
Update: После закрытия Yandex XML сервис стал платным, можно воспользоваться им или любым другим сервисом кластеризации, например OverLead.
Получаем список поисковых интентов:
- официальный сайт
- официальный дилер
- модельный ряд
- комплектации
- цена
- купить
- кредит
- лизинг
- рассрочка
- отзывы
- обзор
- тест драйв
- сервис
Добавив их к нашим брендам мы сможем получить «оценку сверху» по всем кластерам запросов для каждого бренда.
Добавить их можно вручную – записываем все бренды в первую колонку, а интенты в первую строку таблицы и перемножив. Но, для того чтобы затем получить список всех брендов в табличном виде придется проделать много монотонной ручной работы:
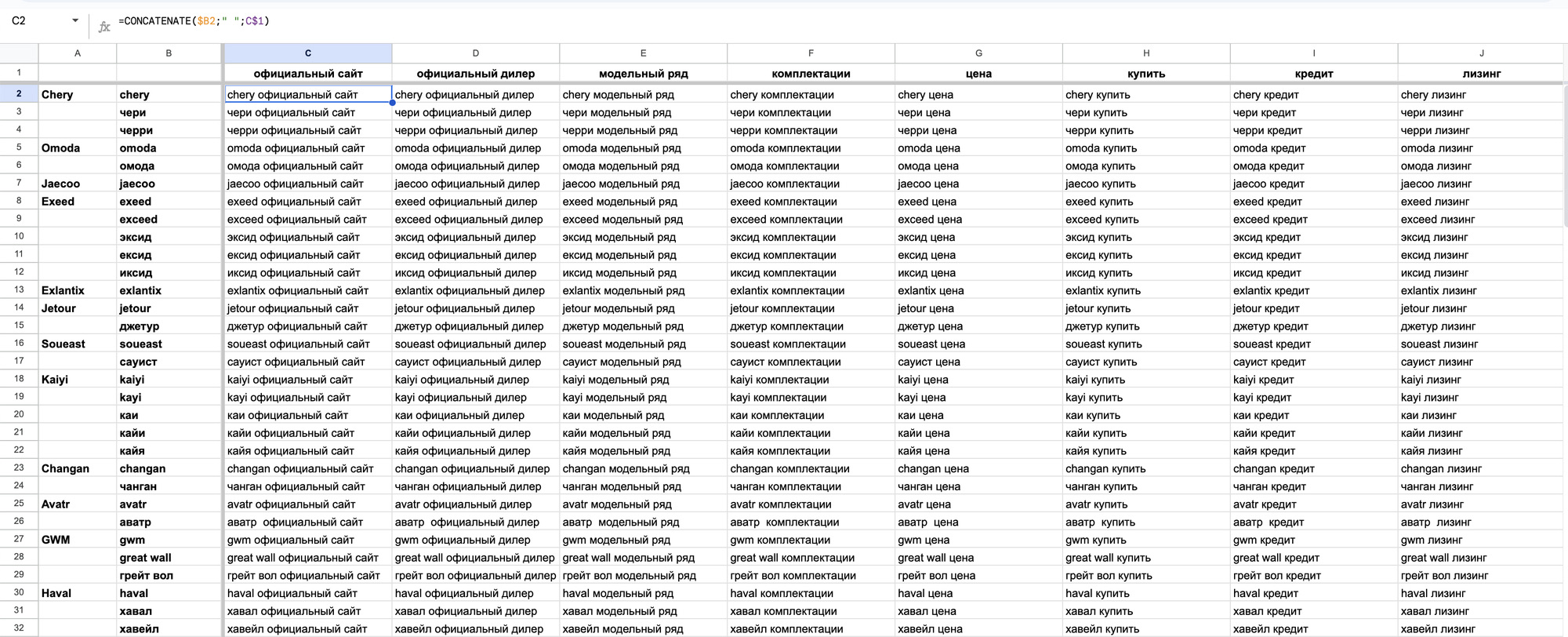
Эту задачу гораздо проще решить с помощью простого цикла на Python и записать обратно в Google Sheets с помощью библиотеки gspread.
# Импортируем библиотеки import pandas as pd import gspread # Google Sheets Credentials gc = gspread.service_account(filename='./credentials/filename.json') # ID документа в Google Sheets G_SHEET = '1C2ol60IPxUyeZgQdsxDNW5bs48PS6YcCJNL-TpCkvDA' # Название или ID листа в Google Sheets G_PAGE_ID = 'KW List' # Открываем нашу Google-таблицу и забираем оттуда данные sh = gc.open_by_key(G_SHEET) worksheet = sh.worksheet(G_PAGE_ID) list_of_lists = worksheet.get_all_values() # Переводим их в DataFrame и обрабатываем его df = pd.DataFrame(list_of_lists[1:]) df.columns = ['brand', 'keyword', 'word'] # Смотрим что получили df

# Формируем список брендов
brands_list = []
for brand in df.keyword:
for word in df.word[0:13]:
brands_list.append(brand + ' ' + word)
brands_df = pd.DataFrame(brands_list)
brands_df

Теперь вместо 100+ запросов у нас получилось 2000+ запросов без лишнего сбора и кластеризации семантики. Загружаем их в KeyCollector и также парсим сезонности. На этот раз подождать придется подольше (у меня ушло примерно 4-5 часов на сбор данных, я просто оставил Mac с запущенной виртуальной машиной на ночь). Также я дополнительно разложил все фразы на группы для удобства, т.к. тогда при выгрузке группа добавится в отдельную колонку, что позволит объединить словоформы в группы по брендам. (Эту же задачу можно решить при обработке на Python, см. примеры далее по тексту).
На выходе снова получаем CSV с данными о сезонности. И вот теперь для пред-обработки этих данных точно нужно использовать Python, поскольку вручную это будет очень долго.
Загружаем наши данные в Data Frame, переводим таблицу в вертикально-ориентированную при помощи метода .melt
# Считываем данные из CSV файла, полученного из KeyCollector
df = pd.read_csv('cache/season_data.csv', sep = ';')
# Переименовываем колонки
df = df.rename(columns={"Фраза": "Keyword", "Родительская группа": "Brand"})
# Удаляем пустую колонку, которая была в выгрузке
df = df.drop(columns=['Unnamed: 26'])
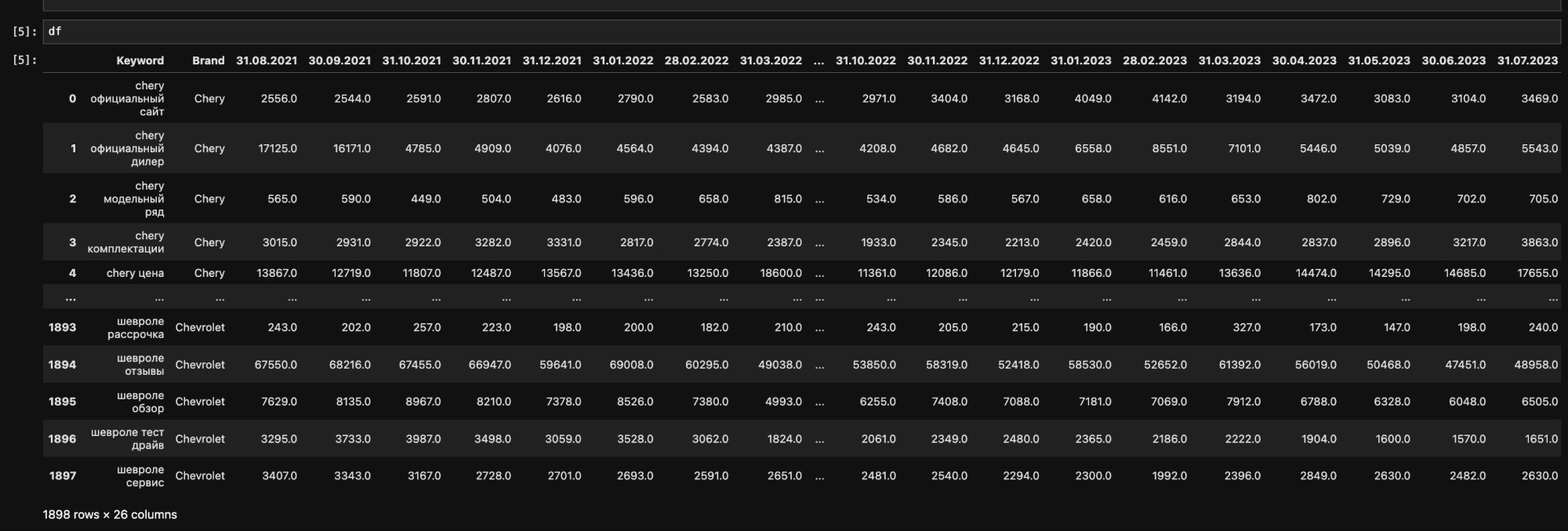
# Преобразуем таблицу в вертикально-ориентированную
stacked_df = pd.melt(df, id_vars=['Brand', 'Keyword'])
# Переименовываем колонки
stacked_df = stacked_df.rename(columns={"variable": "Date", "value": "WordstatPopularity"})
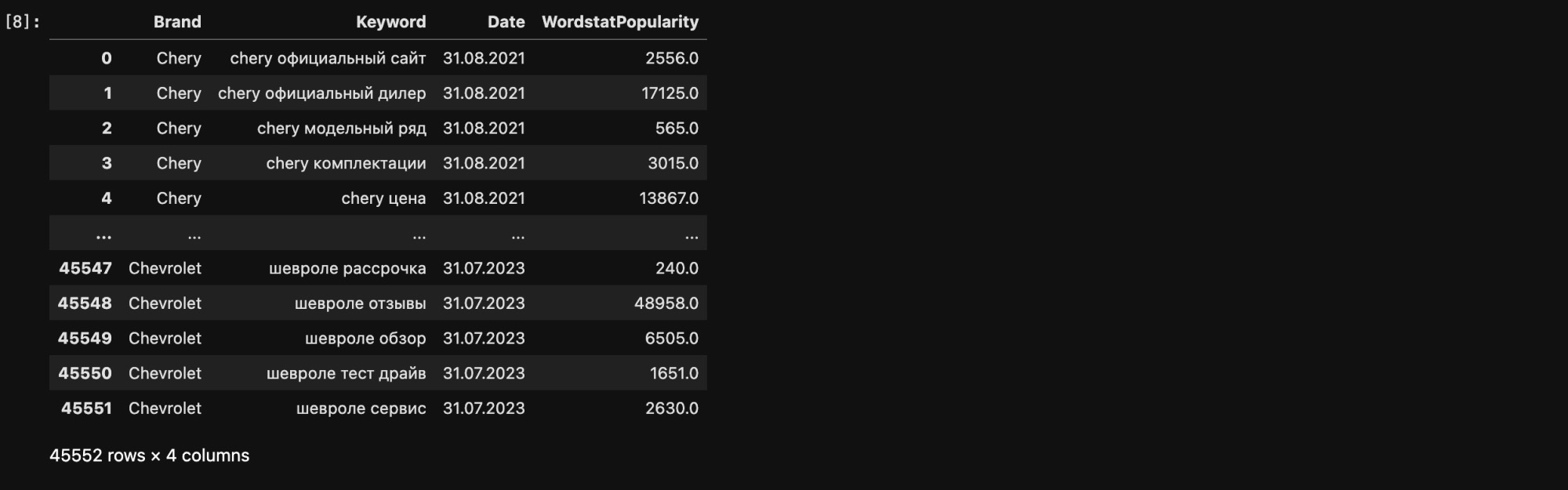
Далее нам надо привести даты в формат yyyy-mm-dd, делаем это при помощи следующего метода:
# Добавим столбец Month с датой в нужном формате stacked_df['Month'] = pd.to_datetime(stacked_df['Date'], dayfirst=True)
Затем мы хотим обогатить наши данные.
Для добавления поискового интента к фразе (что позволит например объединить фразы «… цена» и «…купить» в одну группу) составим список соответствий: «Часть фразы — интент»
intents_dict = {
'.*официальный сайт.*': 'Официальный сайт или дилер',
'.*официальный дилер.*': 'Официальный сайт или дилер',
'.*модельный ряд.*': 'Комплектации и модели',
'.*комплектации.*': 'Комплектации и модели',
'.*цена.*': 'Покупка',
'.*купить.*': 'Покупка',
'.*кредит.*': 'Кредит или лизинг',
'.*лизинг.*': 'Кредит или лизинг',
'.*рассрочка.*': 'Кредит или лизинг',
'.*отзывы.*': 'Обзоры',
'.*обзор.*': 'Обзоры',
'.*тест драйв.*': 'Обзоры',
'.*сервис.*': 'Обслуживание'
}
И обработаем наш дата-фрейм с помощью метода .replace. Как видим, в отдельную колонку у нас добавился поисковый интент.
stacked_df['SearchIntent'] = stacked_df['Keyword'].replace(regex=intents_dict)
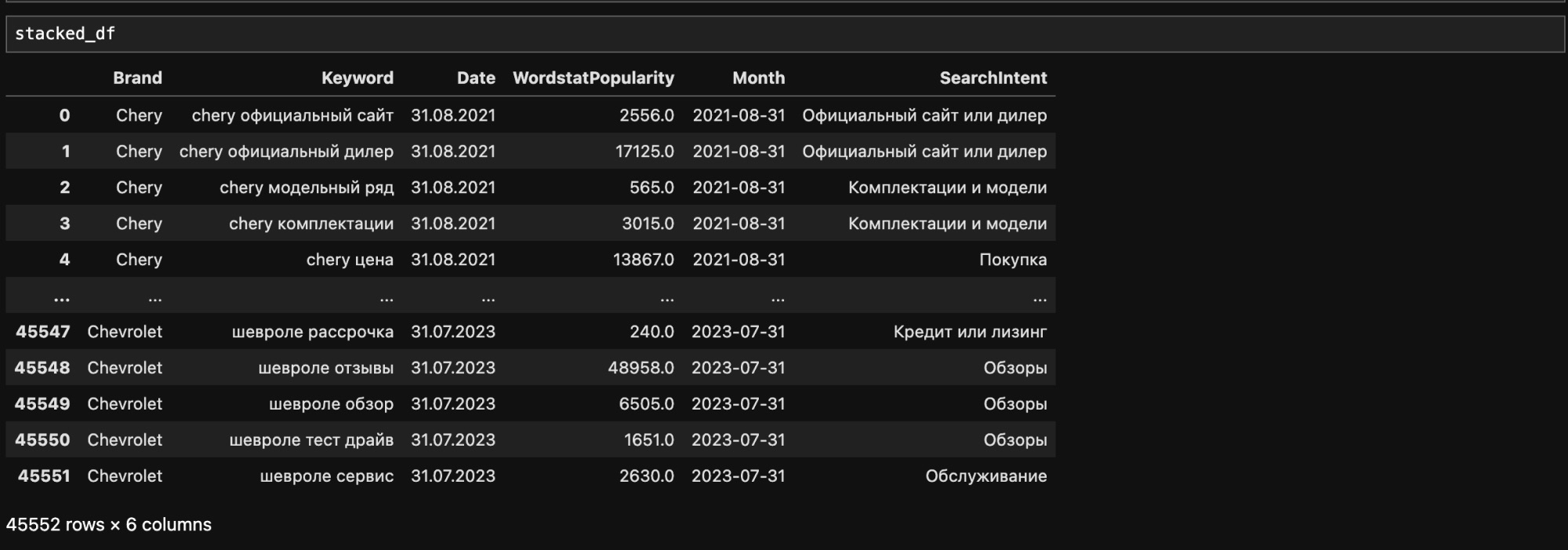
Для добавления страны бренда ко всем запросам составим словарь соответствий бренд — страна и обработаем наш дата-фрейм с помощью метода .map
# Заведем словарь стран
brands_dict_ru = {
'Avatr': 'Китай',
'Baic':'Китай',
'Brilliance': 'Китай',
# ...
'Subaru': 'Япония',
'Suzuki': 'Япония',
'Toyota': 'Япония',
'N/A': 'N/A'
}
# Добавим колонку со странами на основе названий брендов
stacked_df['BrandCountry'] = stacked_df['Brand'].map(brands_dict_ru)
# Удалим не нужную нам колонку Date
stacked_df = stacked_df.drop(columns=['Date'])
В моем примере в дата-фрейме уже есть список всех брендов, поскольку я разбил фразы на группы в интерфейсе KeyCollector, однако эту же задачу можно решить с помощью Python по аналогии с обработкой поисковых интентов, описанной выше.
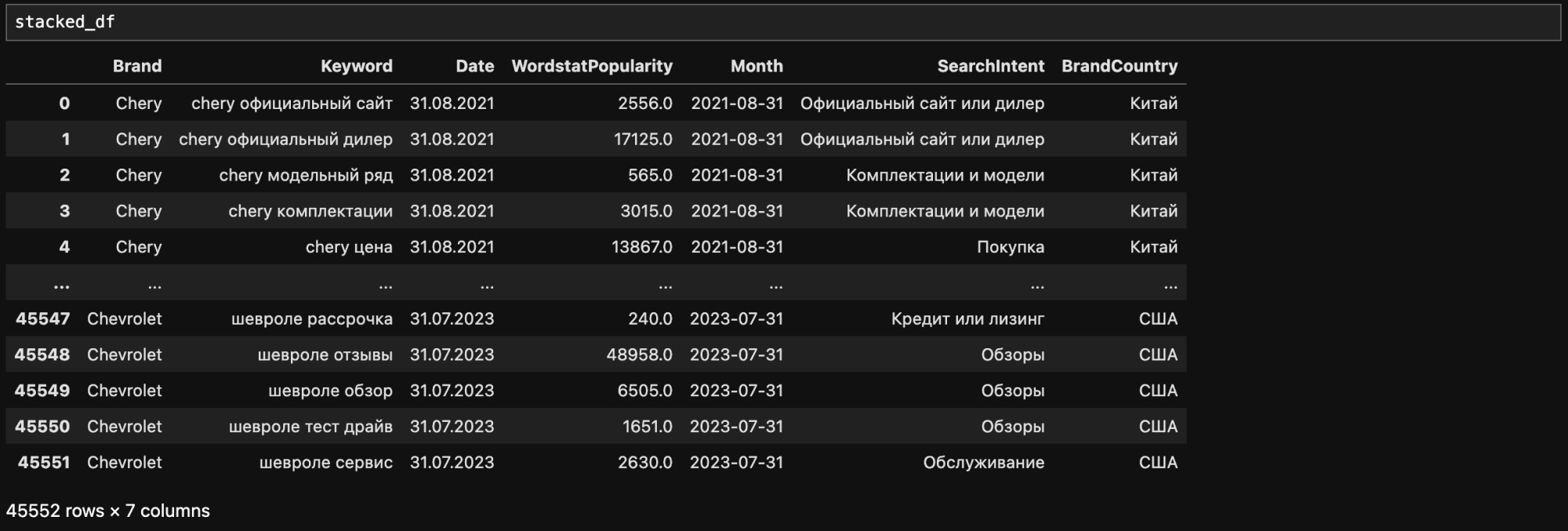
Итак, у нас получилась таблица следующего формата:
- Месяц (
Month) - Страна (
BrandCountry) - Бренд (
Brand) - Интент запроса (
SearchIntent) - Поисковый запрос (
Keyword) - Популярность запроса (
WordstatPopularity)
Мы можем сохранить её в CSV, Google Sheets или ClickHouse. Варианты работы с CSV и Google Sheets неплохо описаны, я буду делать через ClickHouse.
Понадобится подключиться к базе (я использую код из справки Yandex Cloud, ссылка). Там уже написаны функции для записи и чтения. (Единственное что пришлось доработать – убрать проверку SSL-сертификата, поскольку я развернул свой ClickHouse не в Yandex Cloud и не стал настраивать SSL).
Далее удаляем таблицу если она уже создана. Создаем её заново, указав при этом типы данных. Записываем туда наш DataFrame.
# Задаем реквизиты для подключения
# IP-адрес и хост
CH_HOST_NAME = '***.***.***.***'
CH_HOST = f'http://{CH_HOST_NAME}:8123'
# Имя пользователя, базы и таблицы
CH_USER = 'user_name'
CH_DB_NAME = 'db_name'
CH_DB_TABLE = 'database_name'
# Забираем пароль из файла с реквизитами
CH_PASS = open('credentials/password.txt').read().strip()
# Создаем подключение
my_client = simple_ch_client(CH_HOST, CH_USER, CH_PASS)
# Проверяем подключение через получение версии базы данных
my_client.get_version()
# Удаляем таблицу если она есть
q = f'drop table if exists {CH_DB_NAME}.{CH_DB_TABLE} '
my_client.get_clickhouse_data(q)
# Создаем таблицу
q = f'''
create table {CH_DB_NAME}.{CH_DB_TABLE} (
Month Date,
Brand String,
SearchIntent String,
Keyword String,
BrandCountry String,
WordstatPopularity Float32
) ENGINE = MergeTree() ORDER BY (Month) SETTINGS index_granularity=8192
'''
my_client.get_clickhouse_data(q)
# Загружаем DataFrame
my_client.upload(
f'{CH_DB_NAME}.{CH_DB_TABLE}',
stacked_df.to_csv(sep='\t', index =False))
Смотрим, что получилось в базе данных.
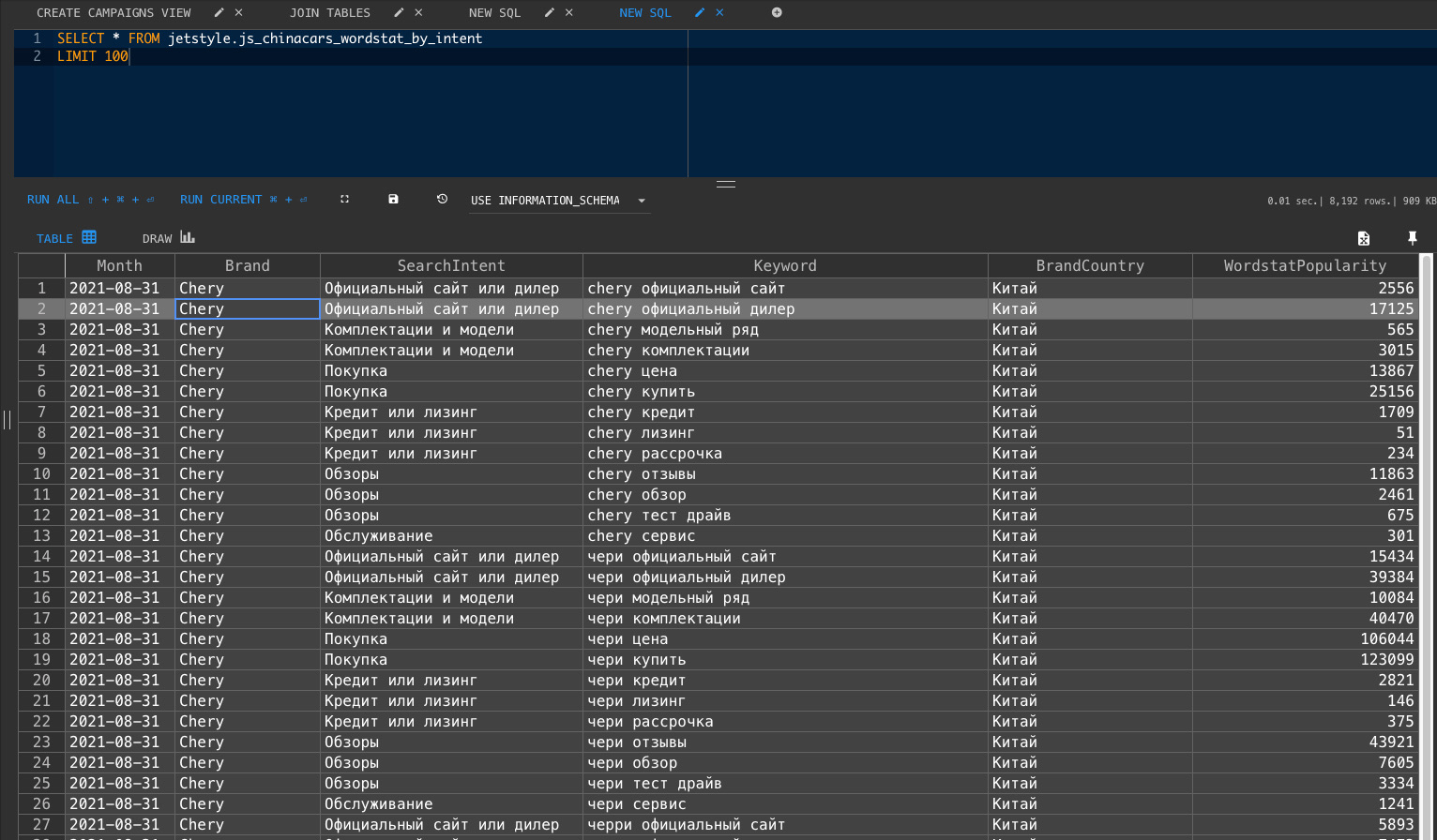
Теперь используя Data Lens подключаемся к нашей базе и строим необходимые чарты.
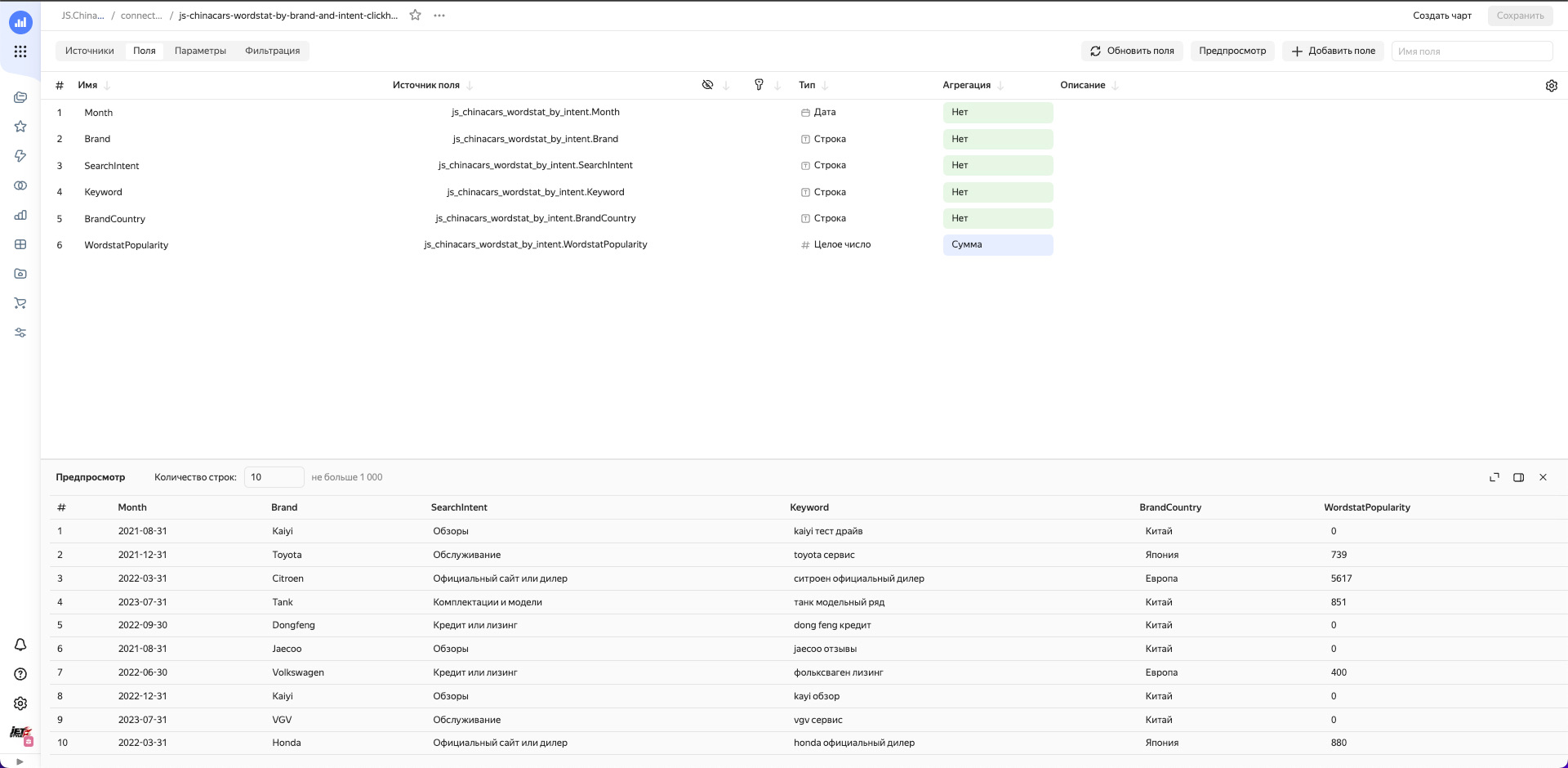
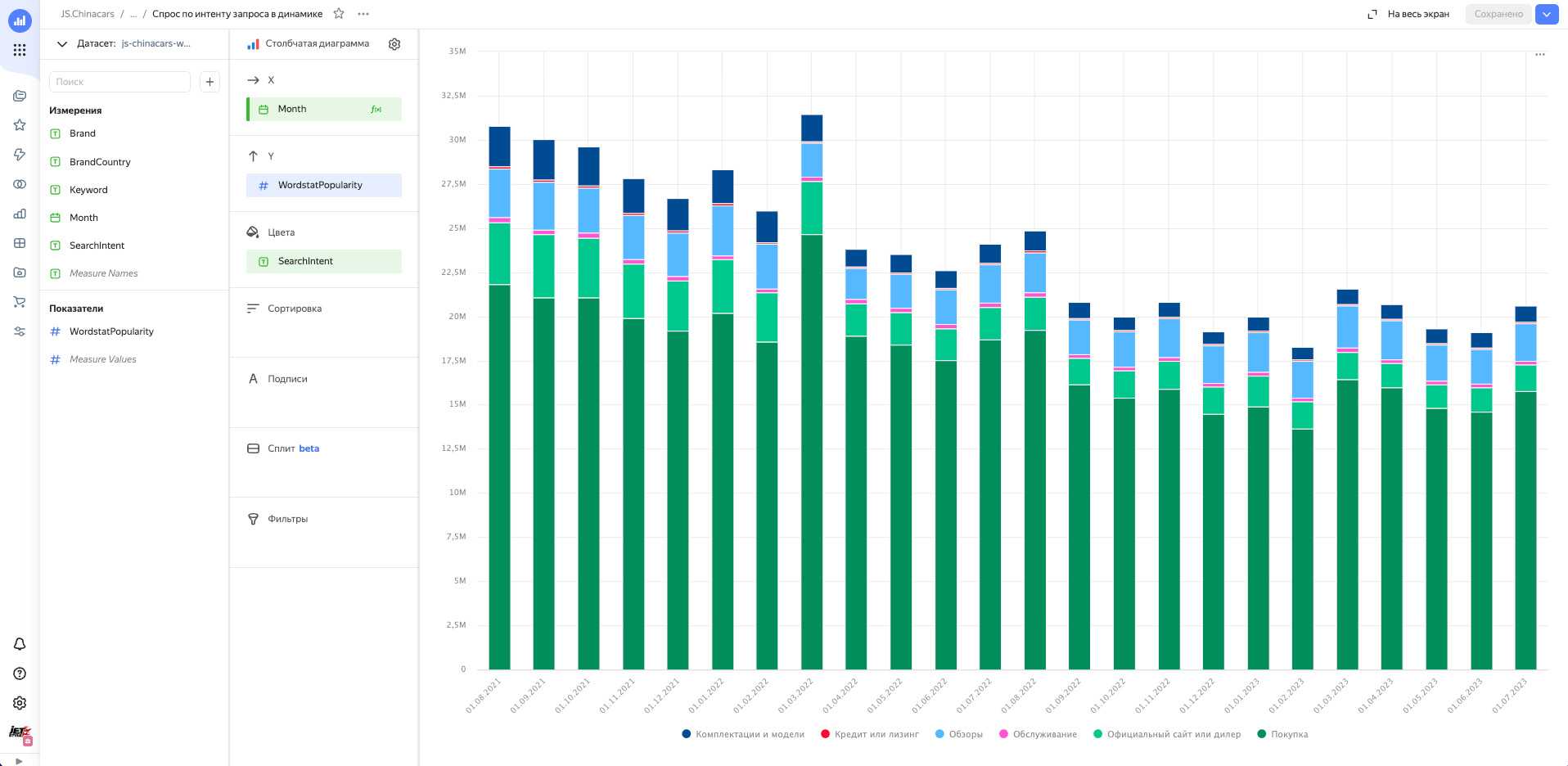
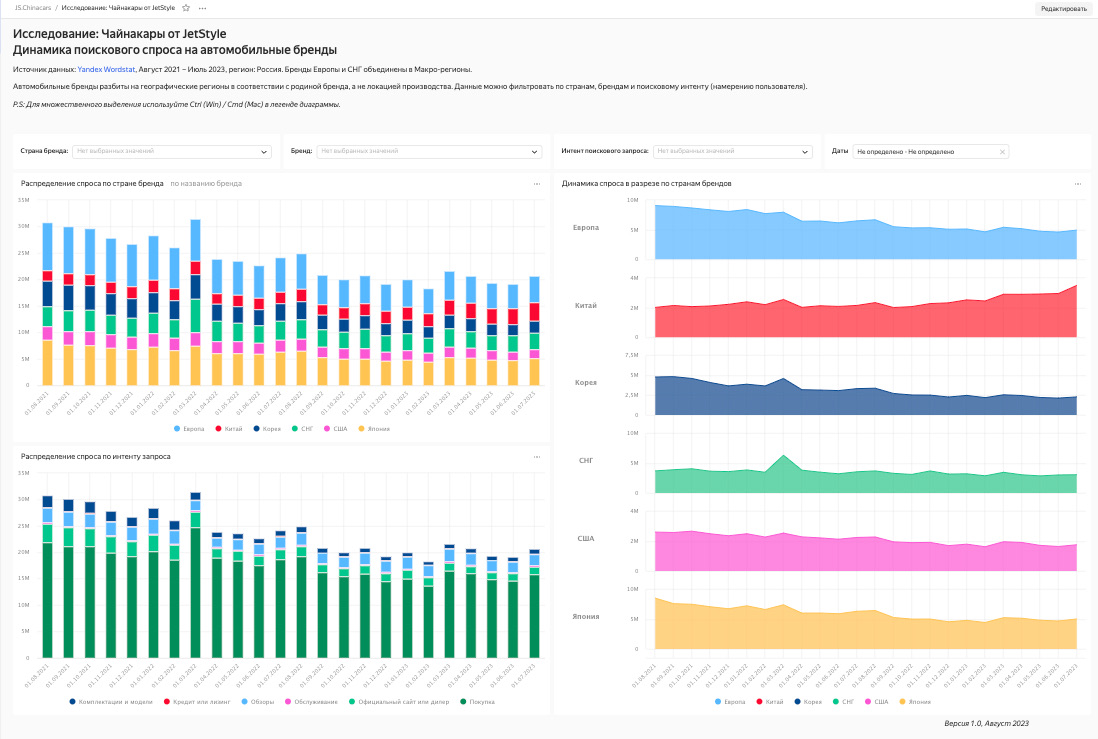
Собранные чарты собираем в дашборд, добавляем туда фильтры.
Результат
- Мы построили наглядную визуализацию того, что происходит со спросом на автомобильном рынке в разрезе по бренду, стране бренда и поисковому интенту в динамике;
- Мы сэкономили время на рутинных операциях: составления списка ключевых слов с помощью перемножения двух списков, подготовке и предобработке данных для визуализации;
- Мы немного прокачались в Python;
- И самое главное — мы видим что происходит со спросом.

